スクリーンスペースでピクセル位置ごとのタスクをソーティング/パッキングするときのCompute Shader
Pixel sorting CS for execution efficiency on GPUs.

コンピュートシェーダーを使って処理をしていると、GPU上で後続の複雑なシェーダーの並列実行性や、メモリアクセスのコヒーレンシーを高めるために、ピクセル(タスク)のパッキング/ソーティングを行いたい場合があります。例えば、ピクセルを、レイの種類ごとにソートしたり、マテリアルIDごとにソートしたり、ライトリストのIDごとにソートするなどが考えられます。 後続のシェーダーのメモリアクセスや、アルゴリズムの分岐方向などは、warp内でなるべく同じになるほうがシェーダー実行速度と、キャッシュヒット率の面で有利です。 そのため、簡単なコンピュートシェーダーでピクセルをソートできれば、後続のシェーダーで、ソートにかかる時間以上の処理速度向上が得られる場合があります。 今回は、スクリーンスペースで、ピクセル位置をタスク要素とみなし、関連付けられた情報(Material ID, Light List IDなど)でピクセルをソートすることを考えてみます。
タイルごとに分割したリストにする
ピクセルをタスクごとにソートすれば、後続のシェーダーで、メモリアクセスや、分岐のコヒーレンシーの向上が得られます。しかし、一般的に、画面全体で完璧にソートされたピクセルリストを作ることは、負荷の高い処理となります。一方で、ソートにかけて良いコストは、後続の複雑なシェーダーの高速化で得られる時間を、安定的に下回る必要があります。トントン程度ならば、メモリと時間の無駄遣いなので、やらない方がシンプルでバグも少ないプログラムになります。
今回は、画面をある程度の大きさ(タイル)に分割して、タイルごとに処理をします。タイルごとにソートされたリストは分かれてしまいますが、タイル同士のメモリアクセス競合が発生しません。結果として、ソート時の並列実行性が高まります。例えばですが、64x64 pixelsでタイルを区切るなら、4096 pixels/tileとなります。レンダリング解像度が2560x1440 pixelsであれば、40x23(22.5) tiles = 920 tilesで処理することになります。
タイルごとにパッキングを行った場合の効率を考えると、32threads/warpのGPUの場合、1タイルあたり最大128 warps分のタスクがあり、タイルごとにパッキングした際のパディングは、最大31threadsで、パディングされるwarpの平均タスク充填率を50%とすると、約0.5warpに相当します。つまり、画面全体で考えると、約410warps分の、処理をしないスレッドが起動されると考えられます。
一方で、画面全体の2560x1440 pixelsのを処理する際に必要なwarp数は、115,200です。画面内のタスク充填率が50%とした場合でも5,7600 warp分のタスクがあり、920tilesに分割してパッキングしたリストを使用した場合に、処理をしないスレッド数が、起動されるスレッド数に占める割合は、おおよそ1%未満程度となります。逆を言えば、起動スレッドに対して、99%以上のタスク充填率になります。
パッキングの効率だけを考えた場合、これ以上タイルのサイズを大きくしてパッキングの効率を上げるという事は、この1%未満の数字を削る行為でしかありません。これ以上タイルサイズを大きくして、パッキング効率を向上させても無駄だといえます。
一方でソーティングに関しては、このように一概に話すことはできません。ソーティングのキーとなる情報(Material ID, Light List IDなど)の種類が、画面内、タイル内に何種類現れるのか、そして、画面をタイルに分割したときに局所性があるのか、また、後続のシェーダーが、ソーティングによって、どの程度メモリアクセスや分岐のコヒーレンシーを得て、どの程度高速化するのかは、実際に動作させるまで分からないでしょう。したがって、パッキング/ソーティングを処理に組み込むときは、精密なプロファイリングが必須です。
簡単な実装を考える
今回は処理タスクは、ピクセルに紐づいているとして、パッキング/ソーティングしたピクセルの座標リストをUAVバッファに格納します。今回はソート用の鍵要素は、画面に描画されたMeshletのIDです。ソート/パッキングされたピクセルリストのUAVバッファは、画面解像度の2560x1440 pixel分を、1Dバッファとして用意します。タイルIDは64x64ピクセルごとに、画面左上からリニアに割り振るとします。ピクセルリストの情報は、ピクセルあたり4byte/pixelで十分です。ピクセルリストはタイルごとに一度だけ、グローバルメモリへのInterlocked操作を使ってオフセットを取得します。タイル境界では、32要素ごとのアラインメントを取ることにします。タイルを跨いだパッキングやソーティングは行いません。
Texture2D<uint3> t_MeshletID : register(t0); // Input. Screen space sort keyes.
RWByteAddressBuffer g_SortedPixels : register(u0); // Output.
RWByteAddressBuffer g_Counter : register(u1); // Counter(4 bytes) for packing pixels in g_SortedPixels. Need to be initialized with zero.
NumThreads は[512, 1, 1]=16 warpsでコンピュートシェーダーを起動します。1スレッドあたり8ピクセル処理すると、ちょうど4096ピクセル処理できます。 groupsharedメモリを使って、ピクセルを分類して数えます。ソートの対象は4096ピクセルなので、最大で4096種類の分類が想定されますが、あくまでも、ソート&パッキングされたピクセルリストを作る理由は、後続のシェーダーの並列実行性の向上であるので、完璧なソートを目指しません。ソート用の鍵(Sort Key)を畳み込んで、127種類(Container Key)として分類します。当然ながら、場合によっては異なる種類のピクセルが同一に扱われてソートされることになりますが、これを許容して処理を行います。これに関する考察は後ほどします。
// Works space for gathering pixels that have the same sorting keys.
static const uint NumContainers = 127; // Number of containers in a tile. Sort keys must be folded into this kinds.
groupshared uint ItemCounts[NumContainers]; // 4 x 127 = 518 bytes.
groupshared uint ItemOffsets[NumContainers]; // 4 x 127 = 518 bytes.
groupshared uint ItemOffsetWrk[NumContainers / WaveSize]; // For storing prefix sum of wave boundaries such as 32, 64 and 96.
groupshared uint TileOffset;
まず初めに、各pixelごとに、ソートのキー要素になるSort Keyを読み出します。今回は、Sort Keyは描画されたMeshlet IDをHash関数を使って計算します。Sort Keyがゼロの場合は、該当ピクセルにタスクがないものとして扱います。Sort Keyは32bitの値ですが、Sort Keyを0~126に畳み込んで、Container Keyにしたあとは、ソート作業では、Sort Keyはもう使いません。ピクセルの位置は、スレッドのIDとイテレーションの回数から算出できるので保持しません。Container Keyごとに、ピクセルを127種類に分類する為に、InterlockedAddで数を数えます。その時取得された値を、コンテナ内のオフセットとして保存しておきます。
for (int i = 0; i < 8; ++i) {
uint2 pixelPos = GetPixelPos(ThID + i * NumThreads, Gid);
containerKeys[i] = 0xFFFFFFFF;
if (pixelPos.x >= screenExtents.x || pixelPos.y >= screenExtents.y) {
// Out of bounds.
continue;
}
uint3 pixelColor = t_MeshletID.Load(int3(pixelPos, 0));
uint sortKey = Hash32_1((pixelColor.x & 0xFF) | ((pixelColor.y & 0xFF) << 8) | ((pixelColor.z & 0xFF) << 16));
if (sortKey == 0) {
// Total black means a empty pixel.
// Hash32_1(0) always returns 0.
continue;
}
uint containerKey = sortKey % NumContainers;
InterlockedAdd(ItemCounts[containerKey], 1, containerLocalIndices[i]);
containerKeys[i] = containerKey;
}
GroupMemoryBarrierWithGroupSync()
次に、WavePrefixSumを使って、127種類のコンテナ同士のオフセットを計算します。
int containerID = ThID;
int itemCnt;
int itemOfs;
if (ThID < NumContainers) { // 0 ~ 126
itemCnt = ItemCounts[containerID];
itemOfs = WavePrefixSum(itemCnt);
if (ThID % WaveSize == WaveSize - 1) {
ItemOffsetWrk[ThID / WaveSize] = itemOfs + itemCnt; // [0]=sum(0:31), [1]=sum(32:63), [2]=sum(64:95)..
}
}
GroupMemoryBarrierWithGroupSync();
if (ThID < NumContainers) { // 0 ~ 126
for (int waveBoundary = 0; waveBoundary < NumContainers / WaveSize; ++waveBoundary) { // for 32, 64, 96
if (ThID >= (waveBoundary + 1) * WaveSize) {
itemOfs += ItemOffsetWrk[waveBoundary];
}
}
ItemOffsets[containerID] = itemOfs;
}
画面全体におけるタイル同士のオフセットを計算する為に、ここで、UAVバッファに対して、InterlockedAddを使ってオフセットを取得します。タスク充填率が常に高い状態になることが分かっている場合は、Interlocked命令を使わずに固定オフセットでタイルごとの情報をしまった方が効率的です。ここでは、タスク充填率が変動するものとして、Interlocked命令でオフセットを計算します。単なるパッキングなら、32要素ごとのアラインメントを取らずにタイトなパッキングにすることも可能ですが、ソートしたリストとwarpのアラインメントが崩れてしまいます。
if (ThID == NumContainers - 1) { // ThID: 126 should have the total number of container entires.
// The first item of each 64x64 tile will be placed with 32 items alignment.
uint TotalAlignedEntriesInTile = Roundup32(itemOfs + itemCnt);
g_Counter.InterlockedAdd(0, TotalAlignedEntriesInTile, TileOffset);
}
GroupMemoryBarrierWithGroupSync();
最後に、ソートされたピクセルリストをストアします。これでこのシェーダーの処理は終わりです。 後続のシェーダーでは、ソートされたピクセルのバッファに、warpごとにアクセスして、処理するピクセル位置を取得することで、warp内の処理が、なるべく同じ処理をするように並べられた状態になるはずです。
for (i = 0; i < 8; ++i) {
if (containerKeys[i] == 0xFFFFFFFF)
continue;
uint2 pixelPos = GetPixelPos(ThID + i * NumThreads, Gid);
uint packedPixelPos = ((pixelPos.y & 0xFFFF) << 16) | (pixelPos.x & 0xFFFF);
g_SortedPixels.Store((TileOffset + ItemOffsets[containerKeys[i]] + containerLocalIndices[i]) * 4, packedPixelPos);
}
Container Keyのコンフリクトについて
今回の例では、処理するピクセル数が、4096に対して、コンテナの数が127です。剰余算でSort KeyをContainer Keyに畳み込んだので、Sort Keyの種類が多い場合は高確率でコンフリクトが発生します。しかし、逆を言えば、Container Keyのコンフリクトが頻繁に発生する状況では、タイル内のSort Keyの種類が多いことが考えられ、この場合は、ソートによるコヒーレンシーの向上効果を得ること自体が難しいと考えられます。それでも、Container Keyは127種類しかないので偶発的なコンフリクトも考えられます。偶発的に発生するコンフリクトをある程度回避し、コンフリクト耐性を高める方法を示します。
コンテナのインデックスとSort Keyの対応付けを管理するため、Sort KeyをgroupsharedメモリにInterlockedCompareAndExchangeを使ってストアします。コンテナが空(0)だった場合は交換が成功します。失敗した場合でも、同一のSort Keyが格納されていれば、そのSort Keyが該当のコンテナをすでに確保しているという意味になるので、該当のコンテナのインデックスを使用します。
一方で、異なるSort Keyがすでに該当のコンテナに格納されている場合は、コンフリクトとなります。この場合は、空きコンテナをリニアサーチします。リニアサーチをどの程度行うかは実装次第で、コンテナを完璧に埋めるには、最悪126回のリニアサーチが必要になります。しかし、今回の実装では、あくまで偶発的に発生するコンフリクトの回避なので、2回しか行いません。最終的にコンフリクトが解決できなかった場合は、そのままコンテナのインデクスを使用します。この場合は、同じコンテナに異なるSort Keyのピクセルが格納されます。
#if RESOLVE_CONTAINER_KEY_CONFLICTS
groupshared uint OriginalKeys[NumContainers]; // 4 x 128 = 512 bytes, to store original sort keys.
#endif
#if RESOLVE_CONTAINER_KEY_CONFLICTS
if (ThID < NumContainers) {
OriginalKeys[ThID] = 0;
}
#endif
#if RESOLVE_CONTAINER_KEY_CONFLICTS
{
const int NumTries = 3;
uint orgVal;
int j;
[unroll]
for (j = 0; j < NumTries; ++j) {
InterlockedCompareExchange(OriginalKeys[containerKey], 0, sortKey, orgVal);
if (orgVal == 0 || orgVal == sortKey) {
// Succeeded to allocate a slot for the sortKey.
break;
}
// Conflict happened. Linear search.
containerKey = (containerKey + 1) % NumContainers;
}
}
#endif
タイル内をコンテナの要素数でソートする
最初の実装例では、タイル内の127種類のコンテナは、コンテナごとの要素数とは関係なくContainer Key順に格納されます。タイルごとに32要素のアラインメントをとりましたが、先頭のコンテナが少量だった場合は、簡単にアラインメントが崩れてしまいます。そこで、コンテナの要素数に基づいて、コンテナをソートしたいと思います。ただしあまり複雑なアルゴリズムを用いてソートすると、コストとパフォーマンスの向上が見合わなくなってしまうので、簡単なソートのみ適用します。ここで使うのは、32要素のRadixSortのようなアルゴリズムです。127種類のコンテナを、32種類に分類して、コンテナがUAVバッファにストアされる順番を入れ替えます。 一番先頭にストアしたいのは、要素数が32にアラインしているコンテナです。これらは32要素にアラインしているバッファにストアすれば、完璧にwarpにフィットします。次に考えられるのは、コンテナの要素数が多いものです。要素数がある程度多いコンテナが隣接している場合は、warp内の分岐が最大2方向で済みます。要素数の多いコンテナ同士の間に少ないコンテナが挟まって、分岐の方向が増えてしまうのを避けれれば十分です。したがって、コンテナの要素数を8で割って、240~8を30~1にマッピングします。31は要素数が32にアラインしているコンテナにアサインします。このインデックスを反転させてソートすれば、アラインしているコンテナが先頭になり、次いで(おおよそ)要素数の大きい順にコンテナがソートされます。
#if SORTING_CONTAINERS
// Sort containers based on their item counts.
{
uint radInput;
uint radLocalIdx;
if (ThID < NumContainers) { // 0 ~ 126
// Each container's item count can be up to 4095 (0x0000_0FFF), however, we just want to put aligned containers and major containers first.
// We can clip this number with 240 (0xF0) which indicates 'major' enough. Also, we can clip minor work items less than 8(>>3) as 'minor' enough.
// So, radixInput can be from 0x00 to 0x1E (0 ~ 30) which is fit into single warp.
// #31 is a special number for containers aligned with 32.
radInput = min(ItemCounts[ThID] >> 3, 30);
radInput = ItemCounts[ThID] % WaveSize == 0 ? 31 : radInput;
// Reverse order. Bigger container first.
radInput = 31 - radInput;
InterlockedAdd(RadixCounts[radInput], 1, radLocalIdx);
}
GroupMemoryBarrierWithGroupSync();
if (ThID < RadixWidth) { // 0 ~ 31
RadixOffsets[ThID] = WavePrefixSum(RadixCounts[ThID]);
}
GroupMemoryBarrierWithGroupSync();
if (ThID < NumContainers) { // 0 ~ 126
int containerID = ThID;
int containerRank = RadixOffsets[radInput] + radLocalIdx;
// Store sorted array. This is the index for storing containers.
RadixSortedContainerIndex[containerRank] = containerID;
}
GroupMemoryBarrierWithGroupSync();
}
#endif
観察
実際にタイルごとにソートした結果を視覚化して確認したいと思います。今回はソートの対象は、Meshletで描画されたMeshletのIDです。特に深い意味はありませんが、Material IDの代わりと考えてもらえれば良いかと思います。ソートしたバッファは、1Dバッファなので、そのまま見ても面白くないので、タイル位置ごとにSort Keyで色付けしたピクセルをリニアに並べています。
タイルサイズは64x64なので、タイルの半分の長さが、ちょうどwarpのサイズになります。

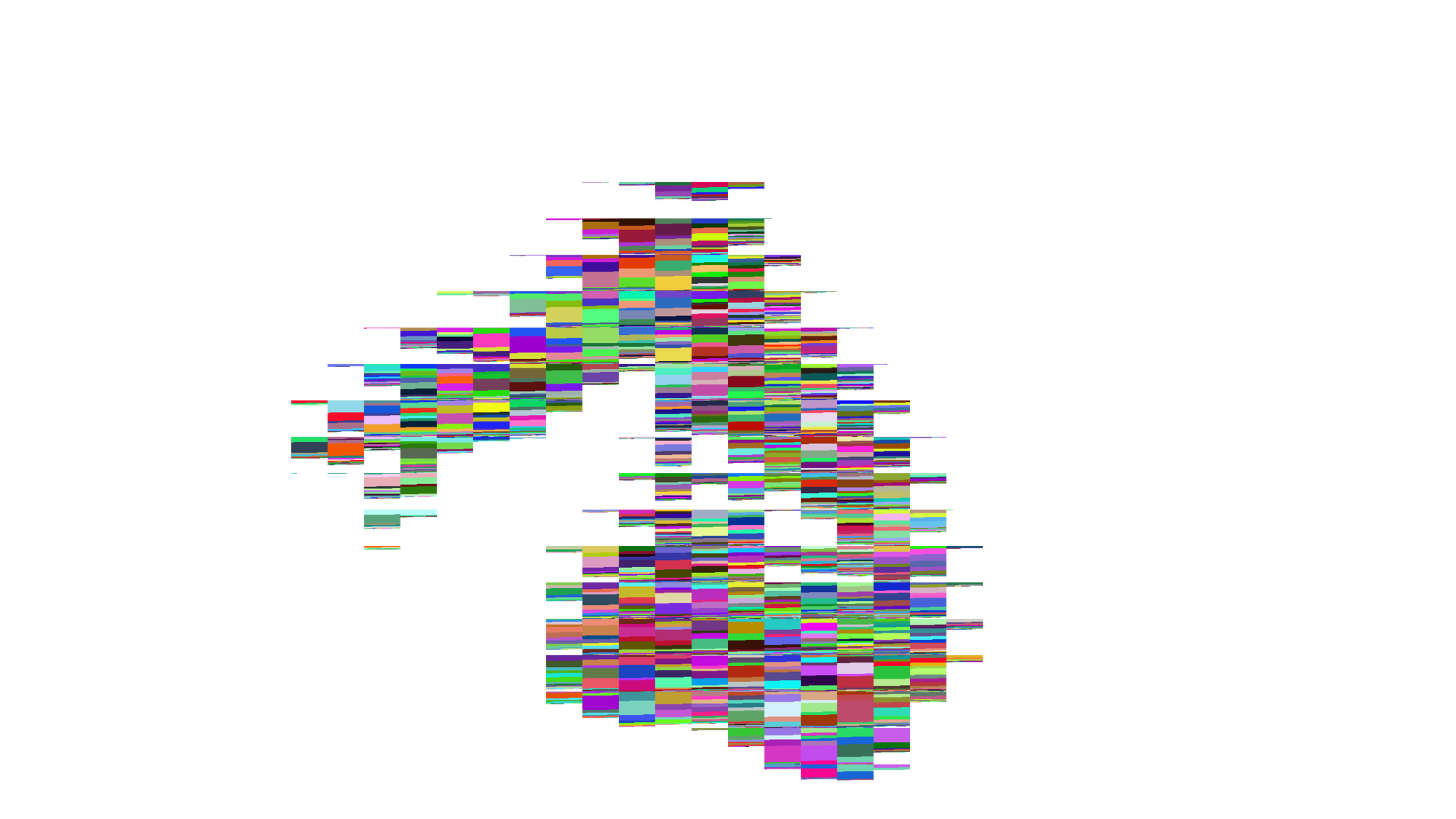
分かりにくいのでCropします。




まず、コンフリクト回避をしていないものは、コンフリクトが発生しているのが視覚化されてよくわかります。見た目がひどいので、コンフリクトの影響が大きいように見えますが、
単なる2種類のコンフリクトであれば、warp内の分岐は2方向なので、見た目ほど酷い実行性能にならないはずです。コンフリクト回避が実行性能に与える影響はおそらく軽微でしょう。
コンテナ要素ごとのソートも、可視化すると良く見えますが、実際はタイルの後半に、要素数の少ないコンテナが密集して、分岐の多いwarpを作ることになるので、全体の速度で考えると
見た目ほど速くなることはないでしょう。
次に処理速度を計測してみます。RTX5080で2560x1440を処理したときに、NSightGraphicsで計測してみます。
処理の計測では、デバッグ用の視覚化処理を省略して計測します。また、負荷を上げるため、オブジェクトのインスタンスの表示数を増やします。


| Sort Keyのコンフリクト回避 | コンテナの要素数によるソート | 実行時間 |
|---|---|---|
| あり | あり | 0.06ms |
| あり | なし | 0.05ms |
| なし | なし | 0.03ms |
| 参考:1Dバッファとデバッグ視覚化バッファのクリア: 0.03ms |
どのDispatchも前後にUAVバリアを設置したので、おおよそ正確な値と思われますが、0.01ms精度での計測は難しいので参考程度で。
考察
もっと並列度を上げるためにいろいろ考えてしまいますが、処理負荷的にこの程度が適切だと思います。 ソートやパッキングにコストをかけ過ぎれば後続の処理が早くなってもトータルで速くならないので、あくまで程々に。
ソース
#if !defined(DEBUG_VISUALIZATION)
#define DEBUG_VISUALIZATION 1
#endif
#if !defined(RESOLVE_CONTAINER_KEY_CONFLICTS)
#define RESOLVE_CONTAINER_KEY_CONFLICTS 1
#endif
#if !defined(SORTING_CONTAINERS)
#define SORTING_CONTAINERS 1
#endif
Texture2D<uint3> t_MeshletID : register(t0); // Input. Screen space sort keyes.
RWByteAddressBuffer g_SortedPixels : register(u0); // Output.
RWByteAddressBuffer g_Counter : register(u1); // Counter(4 bytes) for packing pixels in g_SortedPixels. Need to be initialized with zero.
#if DEBUG_VISUALIZATION
RWTexture2D<float4> g_SortedPixlTex : register(u2); // 2D tex for debug visualization.
#endif
#define NumThreads 512 // Thread group size.
static const uint WaveSize = 32;
static const uint2 screenExtents = uint2(2560, 1440); // For simplicty.
// Works space for gathering pixels that have the same sorting keys.
static const uint NumContainers = 127; // Number of containers in a tile. Sort keys must be folded into this kinds.
groupshared uint ItemCounts[NumContainers]; // 4 x 127 = 518 bytes.
groupshared uint ItemOffsets[NumContainers]; // 4 x 127 = 518 bytes.
groupshared uint ItemOffsetWrk[NumContainers / WaveSize]; // For storing prefix sum of wave boundaries such as 32, 64 and 96.
groupshared uint TileOffset;
#if RESOLVE_CONTAINER_KEY_CONFLICTS
groupshared uint OriginalKeys[NumContainers]; // 4 x 128 = 512 bytes, to store original sort keys.
#endif
#if SORTING_CONTAINERS
// Working space for a radix sort to 'roughly' sort the containers.
static const uint RadixWidth = 32;
groupshared uint RadixCounts[RadixWidth]; // 4 x 32 = 128 bytes
groupshared uint RadixOffsets[RadixWidth]; // 4 x32 = 128 bytes
groupshared uint RadixSortedContainerIndex[NumContainers]; // 4 x 127 = 518 bytes.
#endif
uint TwoRoundXorShiftMulXorShift(uint s1, uint v1, uint s2, uint v2, uint s3, uint x)
{
x ^= x >> s1;
x *= v1;
x ^= x >> s2;
x *= v2;
x ^= x >> s3;
return x;
}
uint Hash32_1(uint x)
{
// https://github.com/skeeto/hash-prospector/issues/19
return TwoRoundXorShiftMulXorShift(15, 0x2c1b3c6d, 12, 0x297a2d39, 15, x);
}
uint Roundup32(uint x)
{
return ((x + 31) / 32) * 32;
}
uint2 DecodeMorton2D64x64(uint mortonCode)
{
uint x = mortonCode & 0xFFF; // 0 ~ 4095
uint y = x >> 1;
x = (x & 0x00000555); // x & 0101_0101_0101b
x = (x | (x >> 1)) & 0x00000333;// & 0011_0011_0011b
x = (x | (x >> 2)) & 0x0000030F;// & 0011_0000_1111b
x = (x | (x >> 4)) & 0x0000003F;// & 0000_0011_1111b
y = (y & 0x00000555);
y = (y | (y >> 1)) & 0x00000333;
y = (y | (y >> 2)) & 0x0000030F;
y = (y | (y >> 4)) & 0x0000003F;
return uint2(x, y);
}
uint2 GetPixelPos(uint pixIdx, uint3 Gid, bool useMortonCode = true)
{
uint2 tilePos = Gid.xy;
uint2 localPos;
if (useMortonCode) {
localPos = DecodeMorton2D64x64(pixIdx);
}
else {
localPos.x = pixIdx % 64;
localPos.y = pixIdx / 64;
}
return tilePos * uint2(64, 64) + localPos;
}
// Dispatch should be called with Dispatch(ScreenExtents.x / 64, ScreenExtents.y / 64, 1)
[numthreads(NumThreads, 1, 1)]
void main(uint3 GTid : SV_GroupThreadID, uint3 Gid : SV_GroupID)
{
const uint ThID = GTid.x;
if (ThID < NumContainers) {
ItemCounts[ThID] = 0;
#if RESOLVE_CONTAINER_KEY_CONFLICTS
OriginalKeys[ThID] = 0;
#endif
#if SORTING_CONTAINERS
if (ThID < RadixWidth) {
RadixCounts[ThID] = 0;
}
#endif
}
GroupMemoryBarrierWithGroupSync();
uint containerKeys[8];
uint containerLocalIndices[8];
for (int i = 0; i < 8; ++i) {
uint2 pixelPos = GetPixelPos(ThID + i * NumThreads, Gid);
containerKeys[i] = 0xFFFFFFFF;
if (pixelPos.x >= screenExtents.x || pixelPos.y >= screenExtents.y) {
// Out of bounds.
continue;
}
uint3 pixelColor = t_MeshletID.Load(int3(pixelPos, 0));
uint sortKey = Hash32_1((pixelColor.x & 0xFF) | ((pixelColor.y & 0xFF) << 8) | ((pixelColor.z & 0xFF) << 16));
if (sortKey == 0) {
// Total black means a empty pixel.
// Hash32_1(0) always returns 0.
continue;
}
// Folding the SortKey with no care will cause accidental conflicts, but we may afford it for cost/perf balance.
uint containerKey = sortKey % NumContainers;
#if RESOLVE_CONTAINER_KEY_CONFLICTS
{
const int NumTries = 3;
uint orgVal;
int j;
[unroll]
for (j = 0; j < NumTries; ++j) {
InterlockedCompareExchange(OriginalKeys[containerKey], 0, sortKey, orgVal);
if (orgVal == 0 || orgVal == sortKey) {
// Succeeded to allocate a slot for the sortKey.
break;
}
// Conflict happened. Linear search.
containerKey = (containerKey + 1) % NumContainers;
}
#if 0
if (j == NumTries) {
// Failed to resolve a conflict. Leave it as is considering cost/perf balance.
// For debugging purpose, kick a DR with an infinite loop to see if this is really happened.
do {
InterlockedCompareExchange(OriginalKeys[containerKey], 0, sortKey, orgVal);
} while (orgVal != (uint) - 1);
}
#endif
}
#endif
InterlockedAdd(ItemCounts[containerKey], 1, containerLocalIndices[i]);
containerKeys[i] = containerKey;
}
GroupMemoryBarrierWithGroupSync();
#if SORTING_CONTAINERS
// Sort containers based on their item counts.
{
uint radInput;
uint radLocalIdx;
if (ThID < NumContainers) { // 0 ~ 126
// Each container's item count can be up to 4095 (0x0000_0FFF), however, we just want to put aligned containers and major containers first.
// We can clip this number with 240 (0xF0) which indicates 'major' enough. Also, we can clip minor work items less than 8(>>3) as 'minor' enough.
// So, radixInput can be from 0x00 to 0x1E (0 ~ 30) which is fit into single warp.
// #31 is a special number for containers aligned with 32.
radInput = min(ItemCounts[ThID] >> 3, 30);
radInput = ItemCounts[ThID] % WaveSize == 0 ? 31 : radInput;
// Reverse order. Bigger container first.
radInput = 31 - radInput;
InterlockedAdd(RadixCounts[radInput], 1, radLocalIdx);
}
GroupMemoryBarrierWithGroupSync();
if (ThID < RadixWidth) { // 0 ~ 31
RadixOffsets[ThID] = WavePrefixSum(RadixCounts[ThID]);
}
GroupMemoryBarrierWithGroupSync();
if (ThID < NumContainers) { // 0 ~ 126
int containerID = ThID;
int containerRank = RadixOffsets[radInput] + radLocalIdx;
// Store sorted array. This is the index for storing containers.
RadixSortedContainerIndex[containerRank] = containerID;
}
GroupMemoryBarrierWithGroupSync();
}
#endif
// Count containers' entires in the tile and sub-allocate buffer to store sorted pixels.
{
int containerID = ThID;
#if SORTING_CONTAINERS
if (ThID < NumContainers) { // 0 ~ 126
containerID = RadixSortedContainerIndex[ThID];
}
#endif
int itemCnt;
int itemOfs;
if (ThID < NumContainers) { // 0 ~ 126
itemCnt = ItemCounts[containerID];
itemOfs = WavePrefixSum(itemCnt);
if (ThID % WaveSize == WaveSize - 1) {
ItemOffsetWrk[ThID / WaveSize] = itemOfs + itemCnt; // [0]=sum(0:31), [1]=sum(32:63), [2]=sum(64:95)..
}
}
GroupMemoryBarrierWithGroupSync();
if (ThID < NumContainers) { // 0 ~ 126
for (int waveBoundary = 0; waveBoundary < NumContainers / WaveSize; ++waveBoundary) { // for 32, 64, 96
if (ThID >= (waveBoundary + 1) * WaveSize) {
itemOfs += ItemOffsetWrk[waveBoundary];
}
}
ItemOffsets[containerID] = itemOfs;
}
if (ThID == NumContainers - 1) { // ThID: 126 should have the total number of container entires.
// The first item of each 64x64 tile will be placed with 32 items alignment.
uint TotalAlignedEntriesInTile = Roundup32(itemOfs + itemCnt);
g_Counter.InterlockedAdd(0, TotalAlignedEntriesInTile, TileOffset);
}
GroupMemoryBarrierWithGroupSync();
}
for (i = 0; i < 8; ++i) {
if (containerKeys[i] == 0xFFFFFFFF)
continue;
uint2 pixelPos = GetPixelPos(ThID + i * NumThreads, Gid);
uint packedPixelPos = ((pixelPos.y & 0xFFFF) << 16) | (pixelPos.x & 0xFFFF);
g_SortedPixels.Store((TileOffset + ItemOffsets[containerKeys[i]] + containerLocalIndices[i]) * 4, packedPixelPos);
#if DEBUG_VISUALIZATION
uint2 linearPixelPos = GetPixelPos(ItemOffsets[containerKeys[i]] + containerLocalIndices[i], Gid, false);
uint3 pixelColor = t_MeshletID.Load(int3(pixelPos, 0));
float r = (float)pixelColor.x / 255.0;
float g = (float)pixelColor.y / 255.0;
float b = (float)pixelColor.z / 255.0;
g_SortedPixlTex[linearPixelPos] = float4(r, g, b, 1);
#endif
}
}
shikihuiku
リアルタイムレンダリングが好き