HLSLのWave Intrinsicsについて
HLSLのWave Intrinsicsについて
Wave Intrinsicsは、HLSLのShader Model6.0から導入された新しい組み込み関数群です。
従来の他のHLSL組み込み関数が、単一スレッド内での変数のみを動作の対象するのに対して、
Wave Intrinsicsは、Waveと呼ばれる複数のスレッド間でのデータの交換や演算を行うための組み込み関数となります。
従来は、Compute Shaderなどで、他のスレッドの変数(演算用のレジスタ)が保持する値を参照するには、groupsharedで宣言された変数やUAVなどで宣言されたバッファーに情報を一旦ストアする必要があったうえ、スレッド間の同期命令が必要でした。
Wave Intrinsicsは、Wave内のスレッド間に限定されますが、他のスレッドの変数(演算用のレジスタ)の値を参照したり演算することが出来ます。
これにより、スレッド間のレジスタ空間の共有が可能になり、複数のスレッドで協調的に動作するシェーダーコードが、より記述しやすくなりました。
また、Wave内は命令実行のタイミングが同じであることが(論理上において)保証されていることから、スレッド間同期命令を必要としないのも大きな利点です。
一点注意が必要なのは、Wave IntrinsicsはShader Model 6.0以上に存在する組み込み関数ですが、実際に使用できるかどうかは、ID3D12Device::CheckFeatureSupport()で、D3D12_FEATURE_D3D12_OPTIONS1を調べる必要があります。
用語
ここではWave Intrinsicsに関連する用語を説明します。
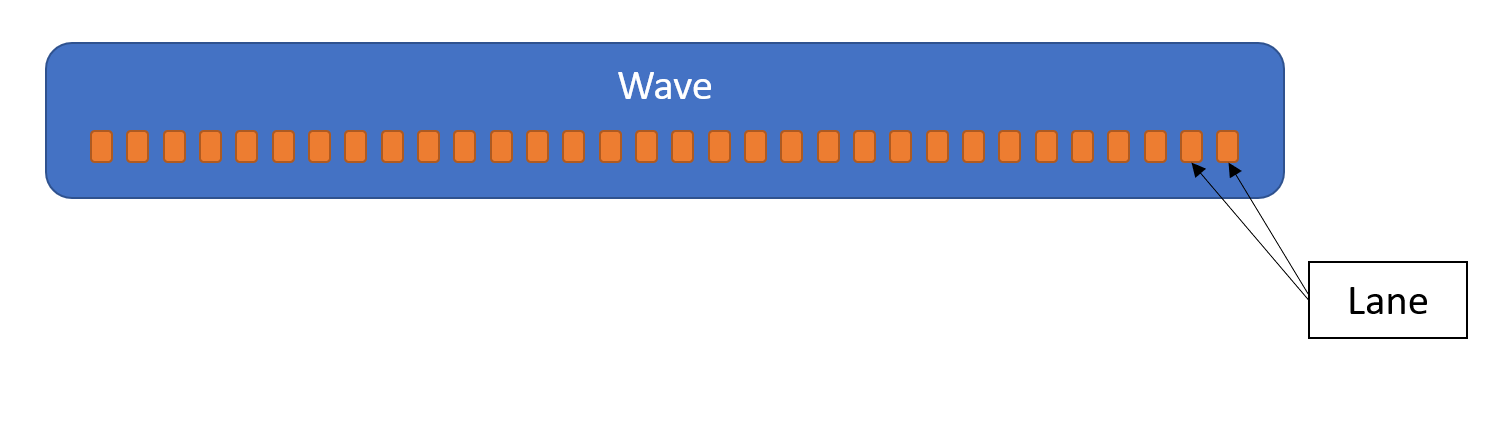
Wave
NVIDIAの用語で"warp"とよばれ、AMDの用語では、“wavefront"と呼ばれてきたものです。命令発行が、同時に行われれるスレッドのグループのことです。
Lane
Waveを構成する個々のスレッドを指します。
以下の図は、一つのWaveの中に32Lane分のスレッドが存在する場合の図になります。この図式を使って様々なWave Intrinsicsについて説明していきたいと思います。
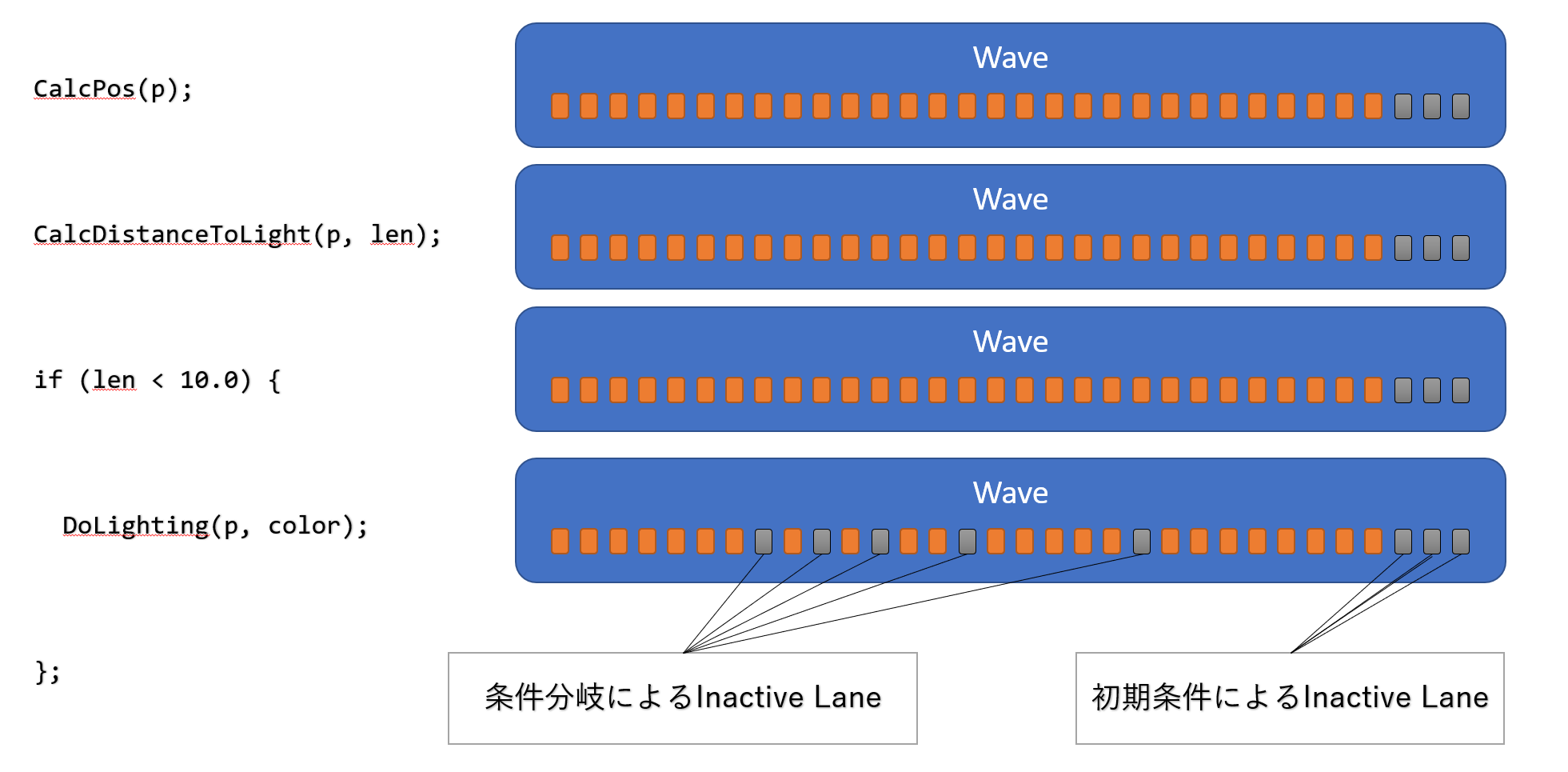
Inactive Lane
Waveを構成する個々のスレッドのうち、命令を実行しないスレッドを指します。
Active Lane
Waveを構成する個々のスレッドのうち、命令を実行するスレッドを指します。
以下の図は、左側のシェーダーコードの実行に伴って変化する、Active LaneとInactive Laneの変化の例を表した図です。右側の3 Laneは、スレッド起動数等の初期条件によるInactive Laneです。 Pixel ShaderやCompute Shaderで必要とされるスレッド数が、Waveの倍数でなかった場合は、Inactive Laneの存在するWaveが起動されます。このようなInactive Laneは、状態が動的に変更されることは無く、終始Inactive Laneのままです。 3行目のIf()による分岐の条件を満たさなかったLaneは、If()ステートで囲まれたコードブロックが終了するまでInactive Laneとなります。Wave内では命令実行は暗黙的に同期する決まりになっているので、Inactive Laneはその間なにも実行せず、他のLaneが該当コードブロックの実行を完了するまで待ちます。 図にはありませんが、If()ステートのコードブロックの実行が終了すれば、条件分岐によってInactive Laneとなったスレッドは、再びActive Laneへと復帰します。
Quad
先頭から連続する4Lane分づつのスレッドのグループを指します。特にPixel Shaderでは、RenderTargetにおける2x2ピクセルブロックが一つのQuadにアサインされます。 Pixel Shaderにおけるddx/ddyなどのGradient命令や、テクスチャーのLoDの計算は、Quad内の変数の差分によって実現されており、Gradientの計算のみに寄与してPixelを塗らないLane(スレッド)をHelper Laneと呼びます。
以下の図は、とあるプリミティブをレンダリングする際の、QuadとHelper LaneのRenderTarget上での表現とWaveとしての表現の対応図です。

Waveのサイズについて
Wave Intrinsicsを使う上で、Waveのサイズというは非常に重要なファクターで、これを理解すること無しに、効率的な処理をデザインすることは難しいと思います。 NVIDIAのWarpは、伝統的に32 Lane/Waveです。対して、AMDのGCNアーキテクチャは64 Lane/Waveで動作しています。 同じくAMDのRDNAアーキテクチャは、Wave32とWave64の二つの動作モードを持ち、それぞれが、32, 64 Lane/Waveで動作しています。 どちらのモードでシェーダーが実行されるかは、ドライバーが決定するようなので、シェーダーは両モードで正しく動く必要があります。結局のところ、32 Lane/Wave、64 Lane/Waveの両方をサポートすることができれば、NVIDIA, AMDの両GPUに対応したアプリケーションとなるはずです。
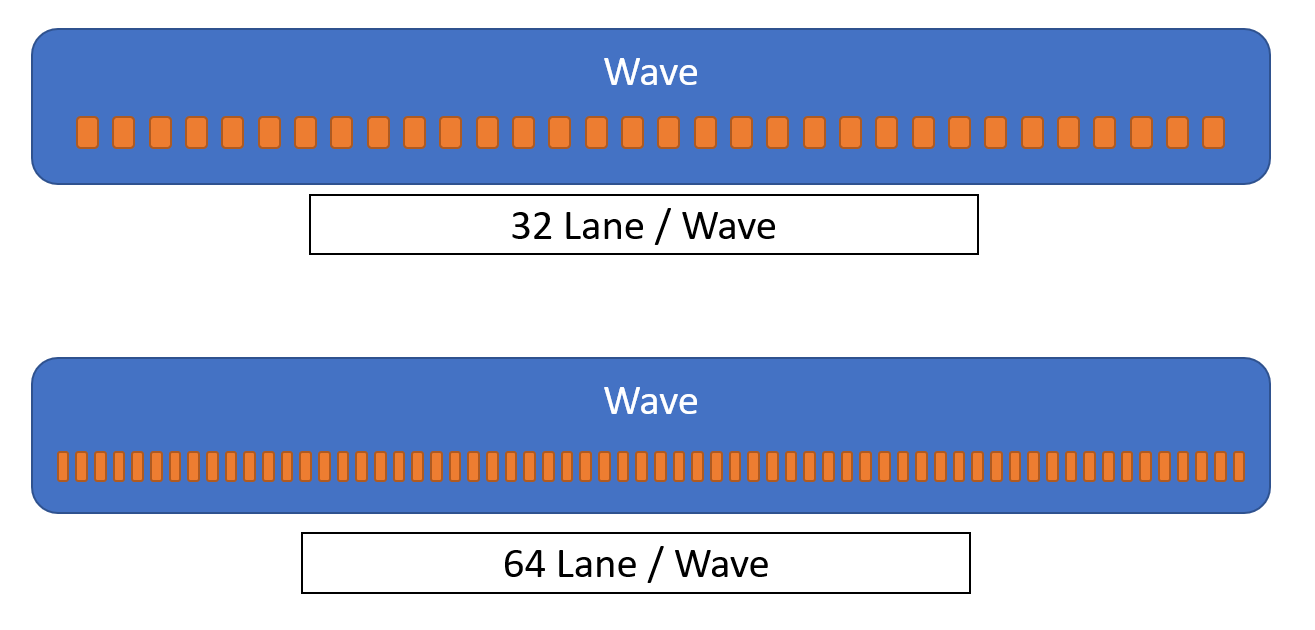
ID3D12Device::CheckFeatureSupport()のD3D12_FEATURE_D3D12_OPTIONS1では、Wave Intrinsicsの使用の可否についてとともに、使用される可能性のあるWaveのサイズの上限値と下限値が返されます。
したがって先のRDNAの様に、単一のアーキテクチャでも、Waveのサイズは可変であると考える必要があるのかもしれません。しかし、WaveのサイズのAPI仕様としての上限値と下限値である 4 と 128 はあまりにもかけ離れているため、Waveのサイズに依存するコードを記述する際に、すべてのWaveのサイズをサポートすることは非現実的です。また、実際には使用されないWaveのサイズのためにコードを書くのも無駄だと思います。したがって、現実的な実装方法としてはD3D12_FEATURE_D3D12_OPTIONS1でWaveのサイズの上限値と下限値をチェックし、32と64の範囲ならば、Wave Intrinsicsを使ったシェーダーコードを使用し、そうでない場合はWave Intrinsicsを使用していないフォールバックのシェーダーコードを実行するか、エラーを出力して動作を終了するべきだと思います。
Waveのサイズは、WaveGetLaneCountというWave Intrinsicsを使って取得できます。しかし、これは裏を返せば、D3D12_FEATURE_D3D12_OPTIONS1のWaveの上限値と下限値に幅がある場合は、HLSLのシェーダーコードを実行するまで、Waveのサイズが分からないという事になります。(これはAPIのデザインの問題だと思います。)
WaveのサイズとThread Groupのサイズについて
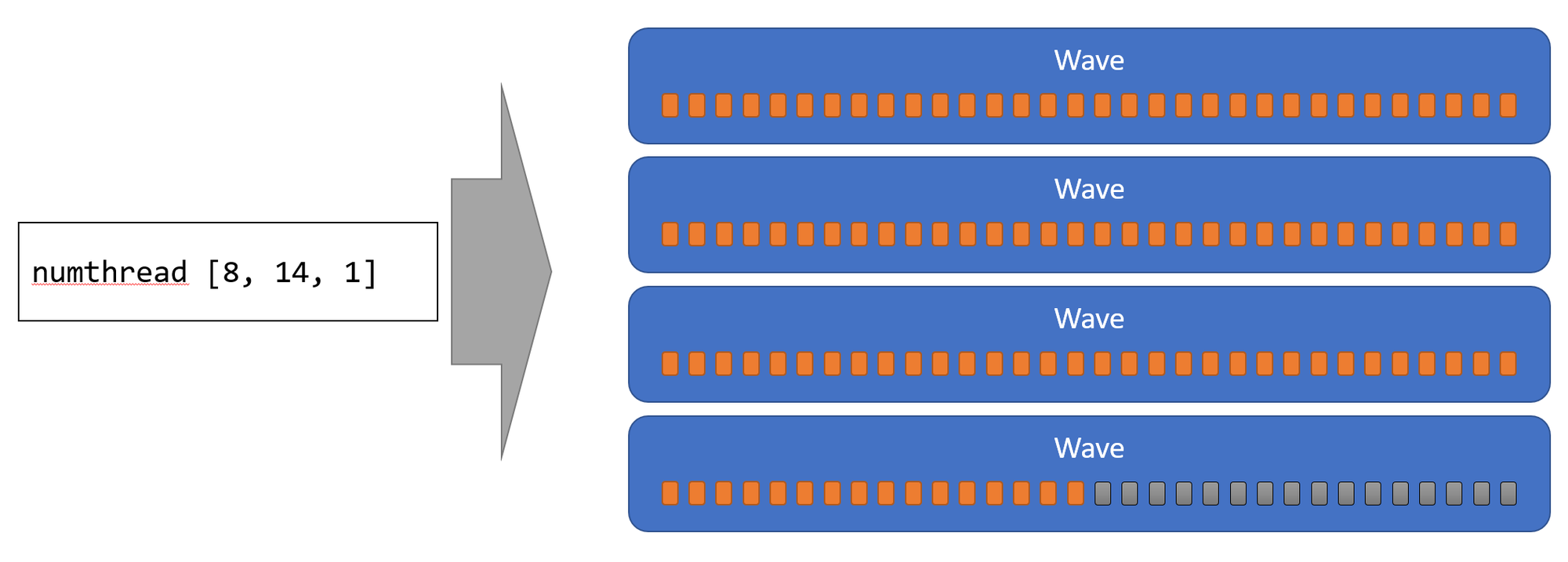
Wave Intrinsicsは、あくまでWaveのサイズを基準とした動作になっていて、Compute Shaderのnumthreadsの大きさは、Waveのサイズとは関係ありません。ただし、Wave Intrinsicsを使う場合は、numthreadsの大きさはWaveのサイズを意識したものが良いと思います。
WaveのThread Group内でのマッピングは、Row Oriented (X軸優先)です。(ただし、これを明記しているドキュメントが見当たらなかったので注意が必要です。)numthreadsの大きさが、Waveのサイズの倍数でなかった場合は、シェーダーが実行される前からInactive Laneが存在するWaveが起動されます。この場合、Waveのサイズ分のスレッドがすべて動作していることを前提として記述されたシェーダーは、動作が破綻するので注意が必要です。
現状では、ID3D12Device::CheckFeatureSupport()のD3D12_FEATURE_D3D12_OPTIONS1の返すWaveのサイズの上限値の倍数をnumthreadsの大きさとすることで、このような事態を回避する事ができると思います。
PixelShaderとWave Intrinsicsについて
(これも明記しているドキュメントが見当たらなかったので注意してください)
Pixel Shaderでは、すべてのWave Intrinsicsの使用が許されています。しかし、Pixel Shaderにおける描画ピクセルとWaveやLaneの対応は、描画されるプリミティブの位置と、GPUとドライバー、そしてPixel Shaderのソースコードによって決まると考えられます。
シンプルな例では、ピクセルシェーダーのスレッドは描画されるプリミティブのピクセルと一対一の関係で起動されると思います。ただし、ピクセルシェーダー内で、Gradinet命令(ddx/ddy)を使用したり、テクスチャーのサンプリングにおいて、LoDを明示的に指定しなかった場合は、スレッド間の値(テクスチャサンプリングにおいてはUV値)の差分を計算する必要があるため、起動されるスレッドは2x2ピクセル単位となります。そして、プリミティブとして描画されるピクセルを担当しているスレッドのみがRenderTargetへの出力を行います。残りのスレッドは、Helper Laneとなり、スレッドとして動作しますがRenderTargetへの出力を行いません。
プリミティブの描画においては、必要なスレッド数は必ずしもWaveのサイズの倍数とならないので、シェーダー内で条件分岐を行っていない状態でも、Inactive Laneが存在しているWaveが起動される可能性があります。また、複数のプリミティブが同一のWaveにパッキングされる可能性もあります。Pixel Shader内でWave Intrinsicsを使う場合は、これらの点について考慮する必要があると思います。
Shader Model 6.0のWave Intrinsicsについて
Shader Model 6.0のWave Intrinsicsは以下のカテゴリに分類することができます。
- Wave Query
WaveやLaneの状態取得 - Wave Vote
Wave内でのbooleanステート確認 - Wave Broadcast
Wave内で特定のLaneの変数値の取得 - Wave Reduction
Wave内での変数の演算 - Wave Scan and Prefix
Wave内での変数の演算(自身より小さいLane Indexに限る) - Quad-wide Shuffle operations
Quadを動作対象とした、変数値の取得
Wave Query
WaveのLane数と、Lane Indexを調べるためのIntrinsicsです。
加えて、Wave内で自身が先頭のActive Laneかどうかを返す、WaveIsFirstLaneが含まれます。
WaveGetLaneCount
WaveのLaneの数を返します。全てのLaneで同じ値を受け取ります。
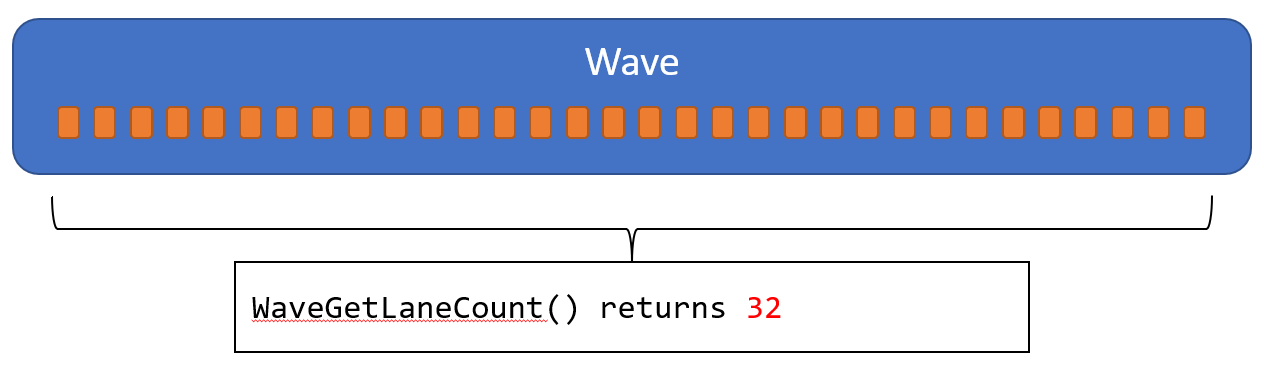
WaveGetLaneIndex
Wave内での該当LaneのIndexを返します。個々のLaneで異なる値を受け取ります。

WaveIsFirstLane
bool値を返します。ActiveLaneの中で最小のLane IndexのLaneのみtrueが返されます。残りのLaneはfalseが返されます。

Wave Vote
Wave内の他のActive Laneのboolのステータスを確認するためのIntrinsicsです。
WaveActiveAnyTrue
引数にbool値を指定します。そして、いずれかのActive Laneがtrueを渡せば、全てのActive Laneにtrueが返されます。そうでない場合は、全てのActive Laneにfalseが返されます。
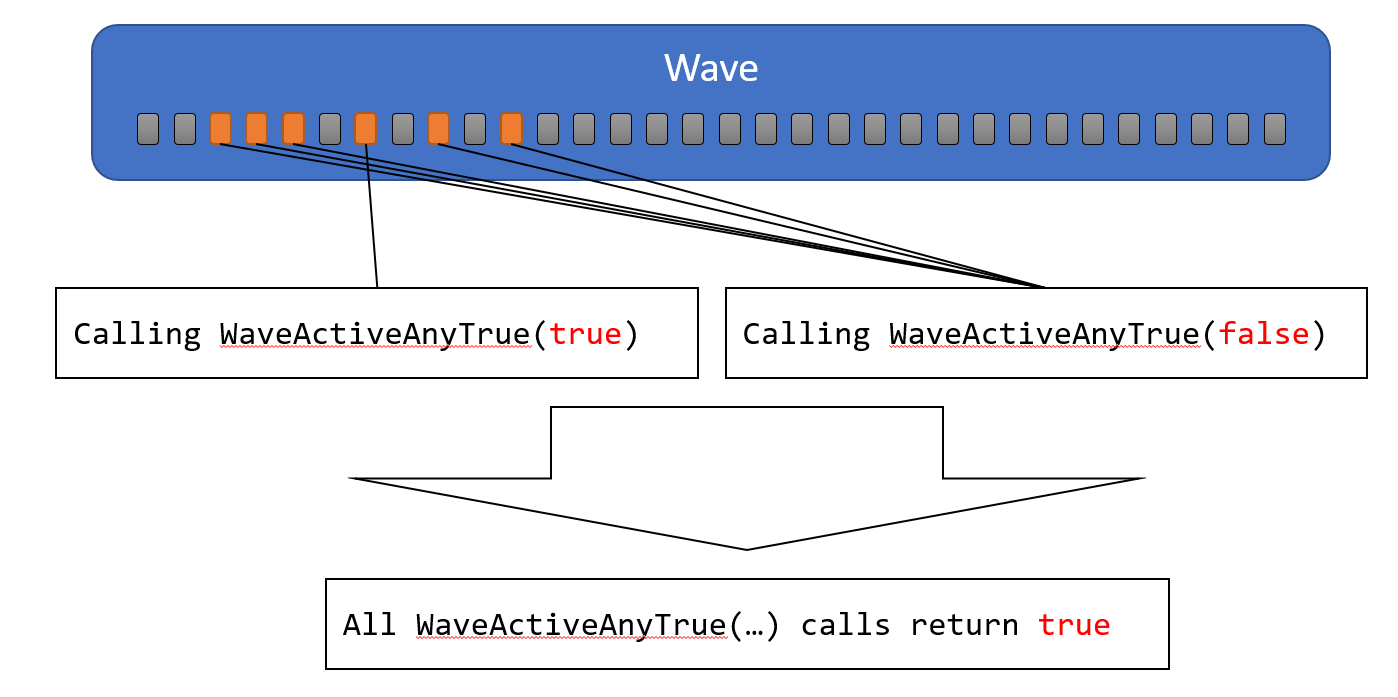
WaveActiveAllTrue
引数にbool値を指定します。全てのActive Laneがtrueを渡せば、全てのActive Laneにtrueが返されます。そうでない場合は、全てのActive Laneにfalseが返されます。
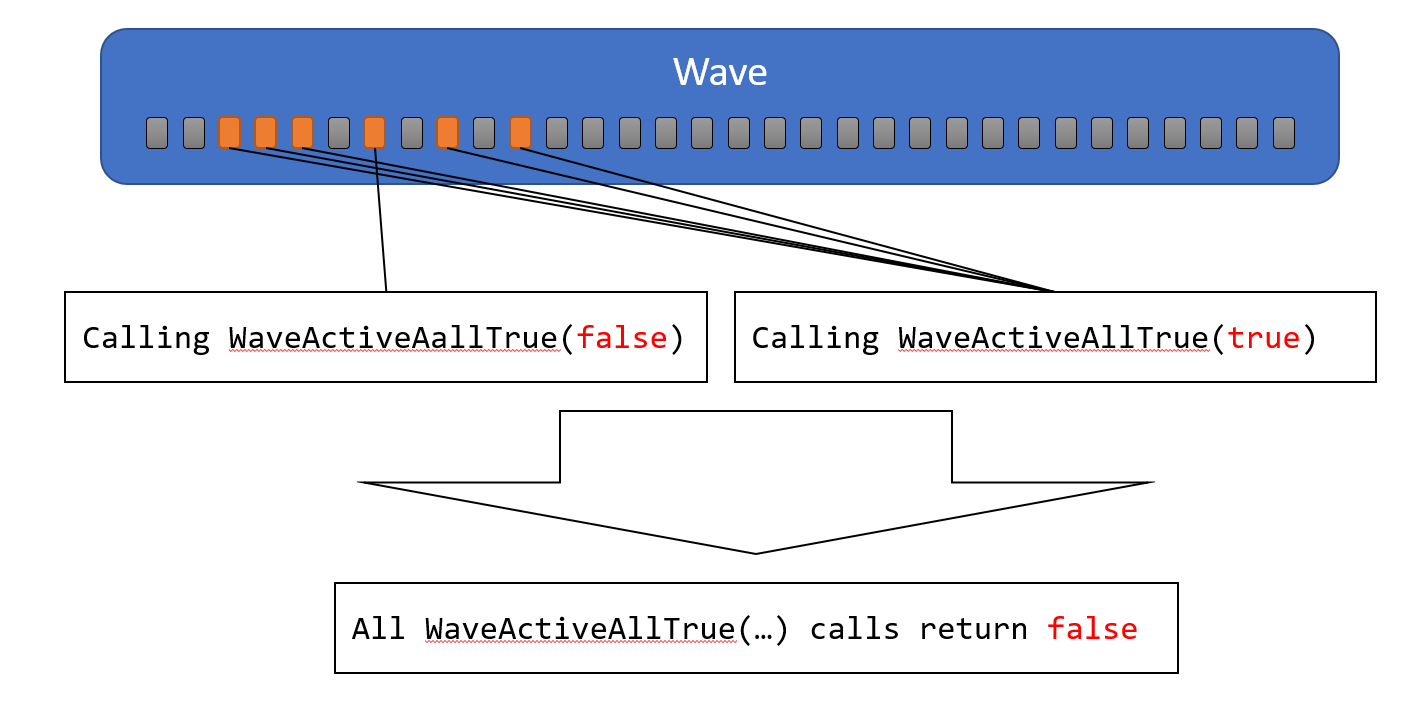
WaveActiveBallot
引数にbool値を指定します。戻り値にuint4を返します。戻り値のuint4は、128bit-wideのビットマスクとなっており、各Active Laneが渡したbool値をビットマスクとして返します。Inacive Laneは暗黙的に0が設定されます。
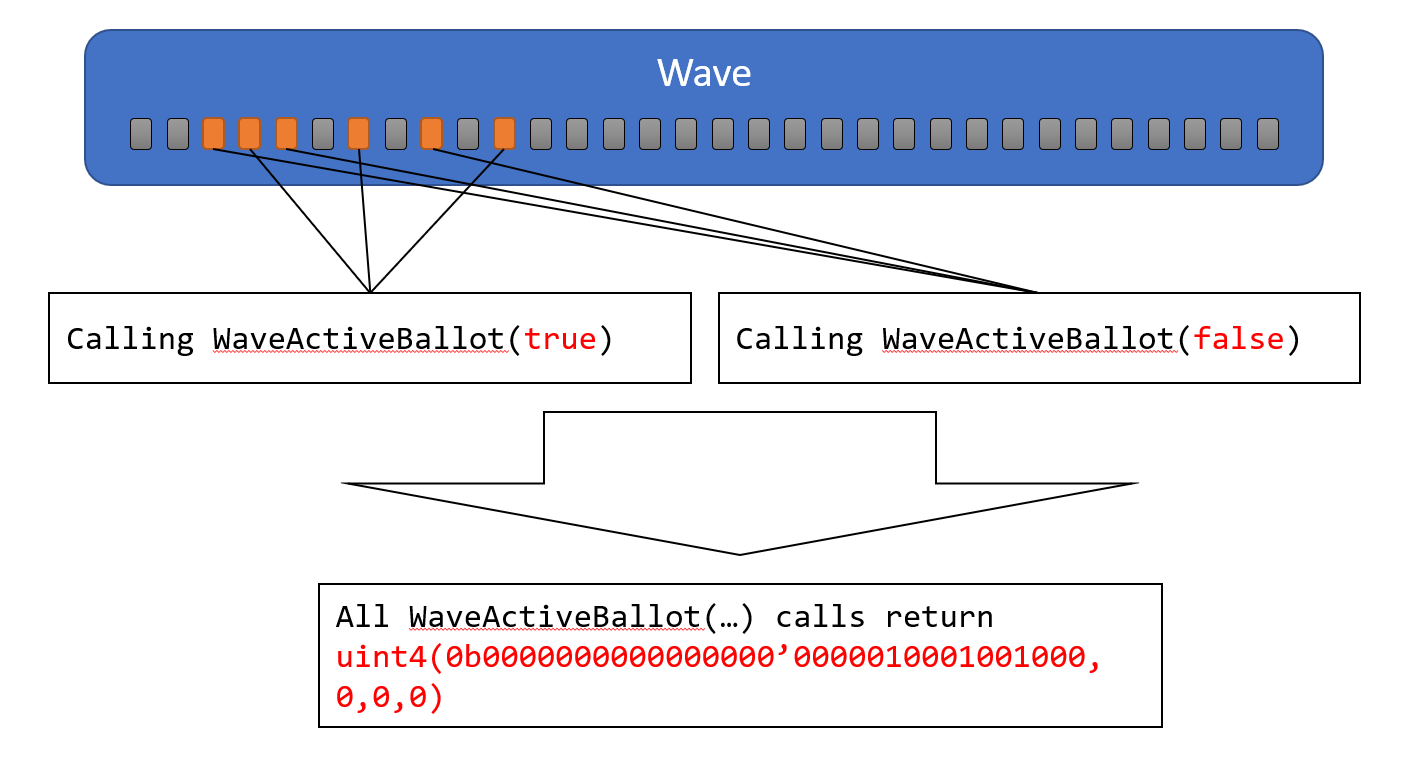
Wave Broadcast
Wave内で、特定のLaneの変数の値を、すべてのActive Laneで取得するためのIntrinsicsです。
WaveReadLaneAt
引数に、読み取りの対象となる変数とLane Indexを指定します。Lane Indexで指定されたLaneの、引数で指定された変数の値を、全てのActive Laneに返します。引数で指定した変数の型と同じ型が返されます。
他にも、引数に指定した変数の型と同じ変数型を返すタイプのWave Intrinsicsがありますが、これらはベクトル型を含め、組み込み型の整数型と浮動小数点型の殆どがサポートされています。

WaveReadLaneFirst
引数に、読み取りの対象となる変数を指定します。Active Laneの中で、最小のLane IndexのLaneの、引数で指定された変数の値を、すべてのActive Laneに返します。
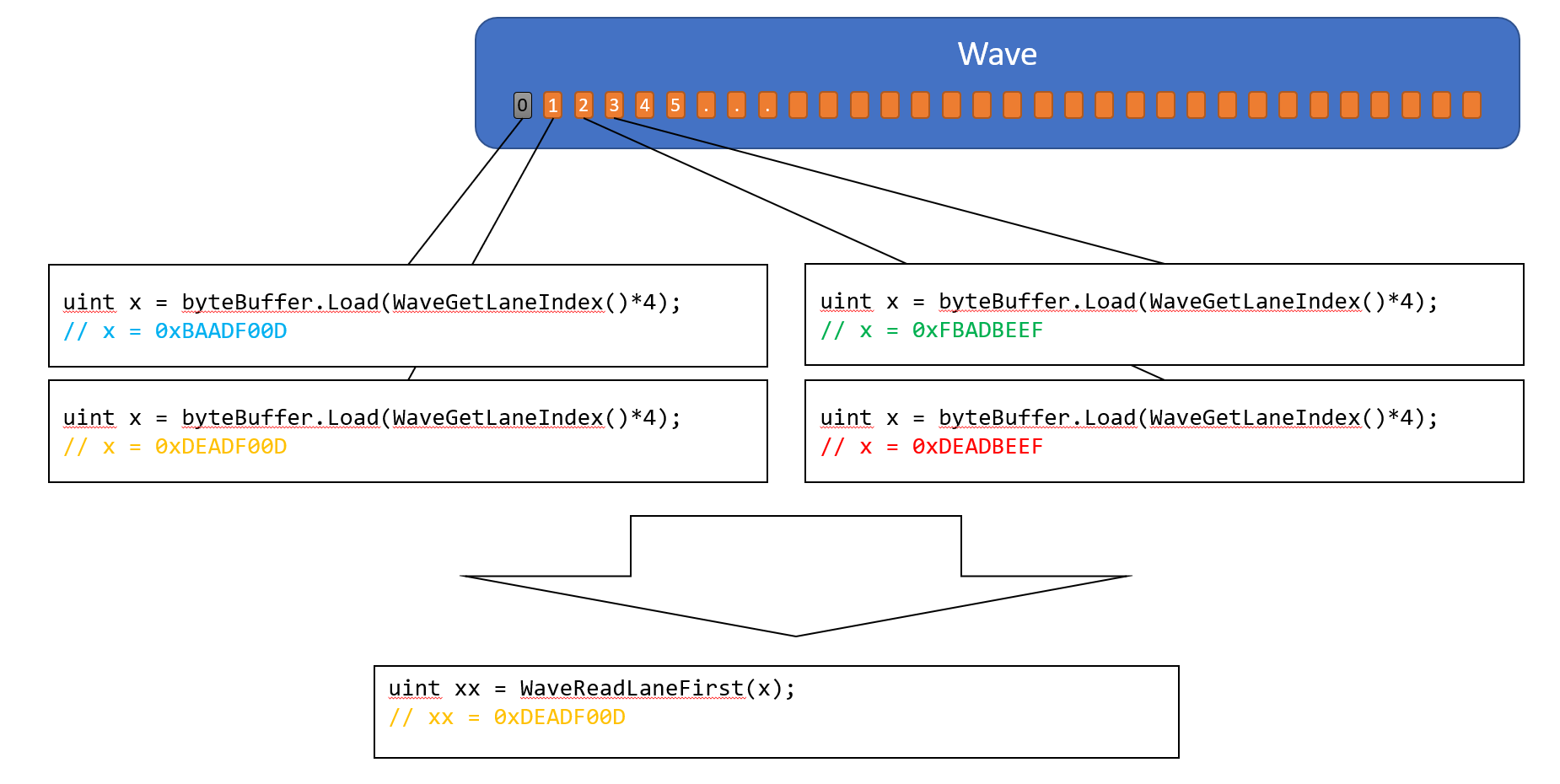
Wave Reduction
Wave内でのActive Laneの変数の値を用いて演算するためのIntrinsicsです。一つの演算結果がすべてのActive Laneに返されます。
WaveActiveAllEqual
引数に、読み取りの対象となる変数を指定します。すべてのActive Laneの変数の値が等しい場合のみTrueを返します。

WaveActiveBitAnd
引数に、読み取りの対象となる整数型の変数を指定します。すべてのActive Laneの変数の値のBitwise AND(論理積)を演算した結果を返します。
WaveActiveBitOr
引数に、読み取りの対象となる整数型の変数を指定します。すべてのActive Laneの変数の値のBitwise OR(論理和)を演算した結果を返します。
WaveActiveBitXor
引数に、読み取りの対象となる整数型の変数を指定します。すべてのActive Laneの変数の値のBitwise XOR(排他的論理和)を演算した結果を返します。

WaveActiveCountBits
引数に、boolを指定します。引数にtrueを指定したLaneの数を、すべてのActive Laneに返します。
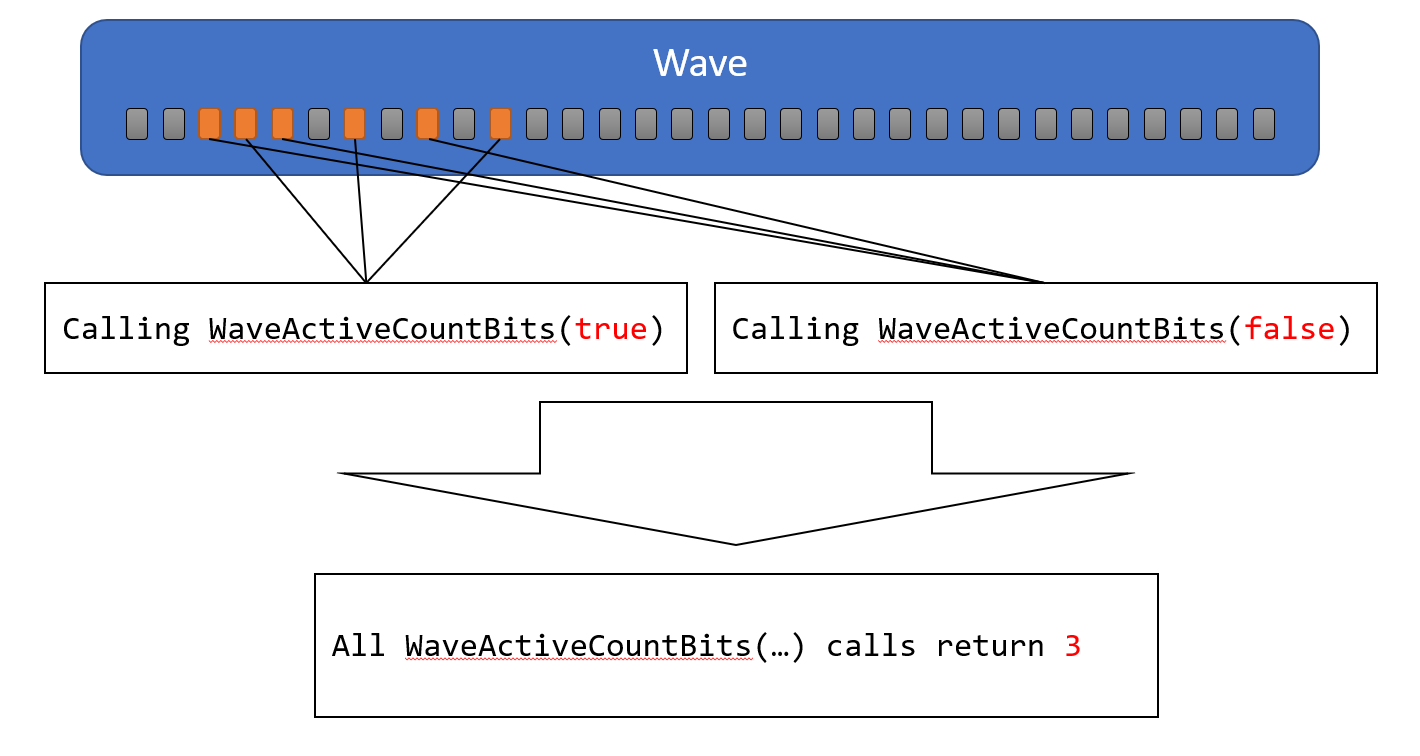
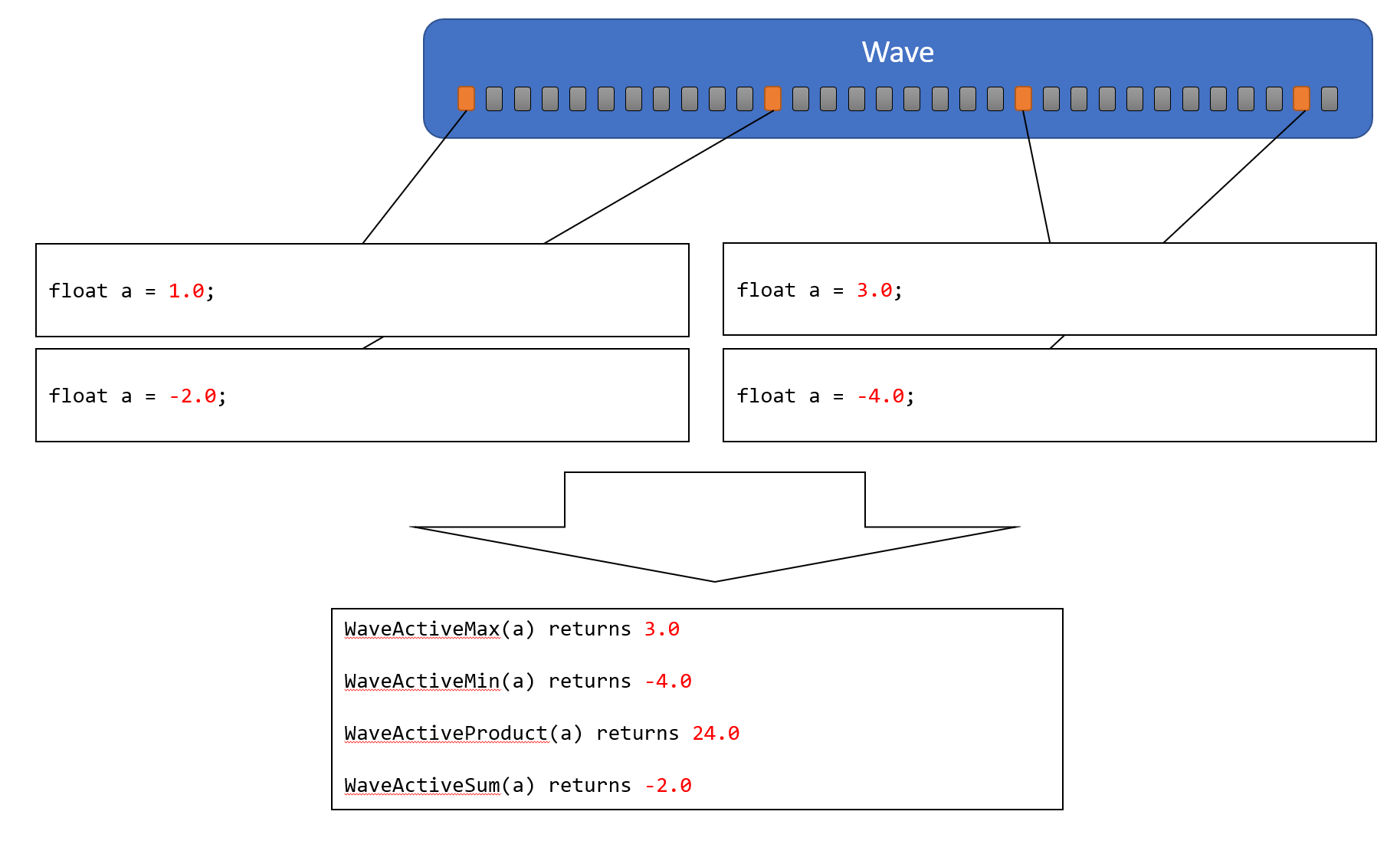
WaveActiveMax
引数に、読み取りの対象となる変数を指定します。すべてのActive Laneの変数の値の中で、最大値を、全てのActive Laneに返します。
WaveActiveMin
引数に、読み取りの対象となる変数を指定します。すべてのActive Laneの変数の値の中で、最小値を、全てのActive Laneに返します。
WaveActiveProduct
引数に、読み取りの対象となる変数を指定します。すべてのActive Laneの変数をの値を乗算した結果を、全てのActive Laneに返します。 演算の順序については、API仕様としての明確な定義が無いので、扱う変数の型や、値の範囲について注意が必要です。
WaveActiveSum
引数に、読み取りの対象となる変数を指定します。すべてのActive Laneの変数の値を加算した結果を、全てのActive Laneに返します。 演算の順序については、API仕様としての明確な定義が無いので、扱う変数の型や、値の範囲について注意が必要です。
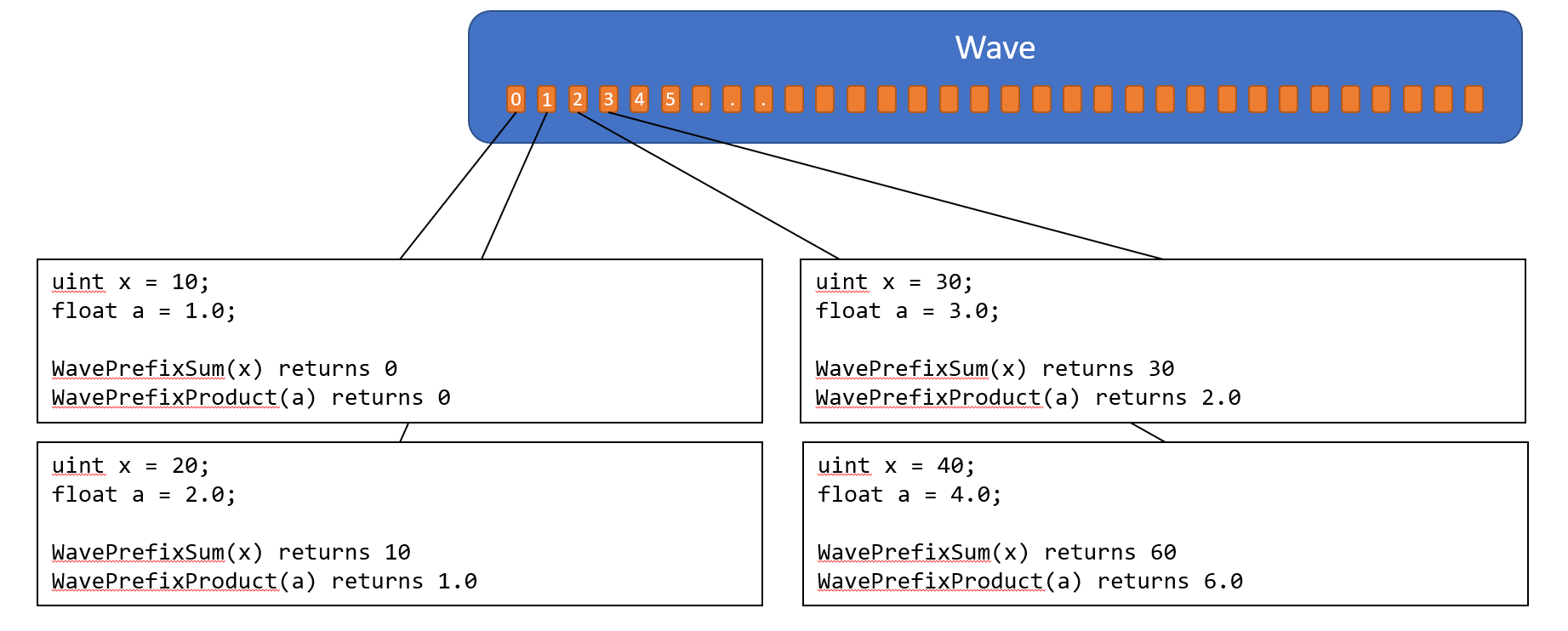
Wave Scan and Prefix
Wave Reduction系に似ていますが、演算の対象が自身のLane Index未満のActive Laneのみです。自身のLaneは演算の対象に含みません。 演算の結果は、基本的にはLaneごとに異なる値が返されることになります。
WavePrefixCountBits
引数にboolを指定します。自身のLane Index未満のActive Laneで、引数にtrueを指定した個数を返します。
WavePrefixSum
引数に、読み取りの対象となる変数を指定します。自身のLane Index未満のActive Laneの、変数の値を加算した結果を返します。
演算の順序については、API仕様としての明確な定義が無いので、扱う変数の型や、値の範囲について注意が必要です。[precise]フラグは無視されます。
WavePrefixProduct
引数に、読み取りの対象となる変数を指定します。自身のLane Index未満のActive Laneの、変数の値を乗算した結果を返します。
演算の順序については、API仕様としての明確な定義が無いので、扱う変数の型や、値の範囲について注意が必要です。[precise]フラグは無視されます。
Quad-wide Shuffle operations
Pixel Shaderでのみ使用可能なWave Intrinsicsです。
(これについては、2020/08現在ドキュメントの表記と実装に食い違いがあります。ドキュメントにはCompute Shaderでも使用可能と表記されており、その場合、Lane Indexの0より4 Laneごとに区切ったLaneがQuadとして扱われるとされています。
しかし実際には、Quad系を使用したCompute Shaderのコンパイル時にopcode 'QuadReadAcross' should only be used in 'Pixel Shader'というメッセージが出力されます。そして、シェーダーの生成にも失敗します。)
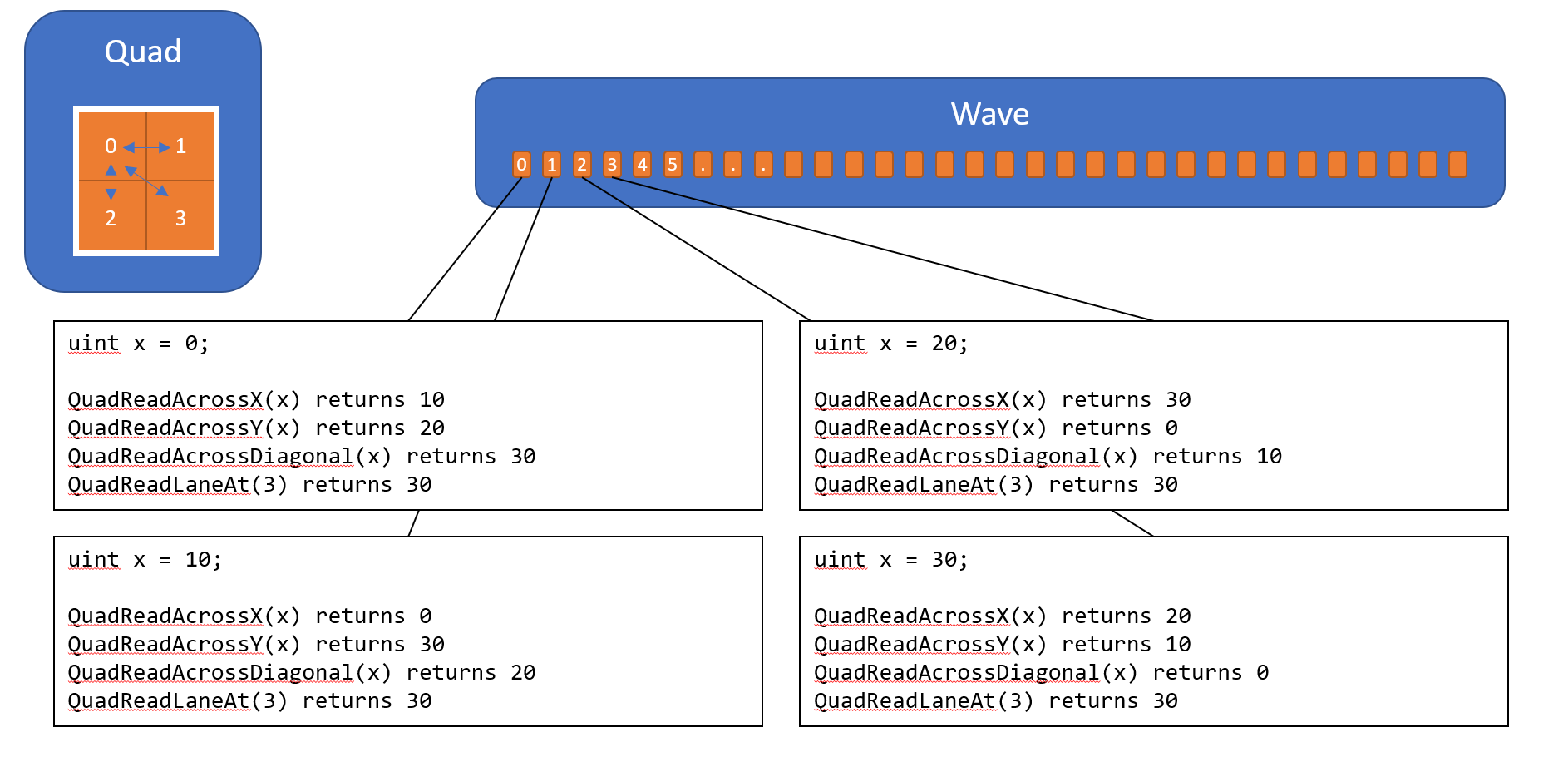
QuadReadLaneAt
引数に、Quad内のローカルのLane Indexと、読み取り対象となる変数を指定します。Quad内で同じ値が返されます。 読み取り対象LaneがInactive Laneだった場合の読み取り結果は未定義なので注意が必要です。 Pixel ShaderにおけるQuad内のローカルのLane Indexは、下図に示した通りRow Orientedとなっています。
QuadReadAcrossDiagonal
引数に、読み取り対象となる変数を指定します。Quad内で互いに対角の位置にあるLaneの値を読み取ります。(例えば、Lane:0はLane:3の値を受け取ります。) (APIドキュメントに明記がありませんが、読み取り対象LaneがInactive Laneだった場合の読み取り結果は未定義なので注意が必要です。)
QuadReadAcrossX
引数に、読み取り対象となる変数を指定します。Quad内で互いに水平の位置にあるLaneの値を読み取ります。(例えば、Lane:0はLane:1の値を受け取ります。) (APIドキュメントに明記がありませんが、読み取り対象LaneがInactive Laneだった場合の読み取り結果は未定義なので注意が必要です。)
QuadReadAcrossY
引数に、読み取り対象となる変数を指定します。Quad内で互いに垂直の位置にあるLaneの値を読み取ります。(例えば、Lane:0はLane:3の値を受け取ります。) (APIドキュメントに明記がありませんが、読み取り対象LaneがInactive Laneだった場合の読み取り結果は未定義なので注意が必要です。)
Shader Model 6.5のWave Intrinsicsについて
Model 6.5で、いくつかの新しいWaveIntrinsicsが導入されています。
WaveMatch
引数に、読み取り対象となる変数を指定します。
戻り値にuint4を返します。戻り値のuint4は、128bit-wideのビットマスクとなっており、各Active Laneの引数で指定された変数の値が、自身のLaneの変数の値と等しい場合に、ビットがセットされます。Inacive Laneは暗黙的に0が設定されます。

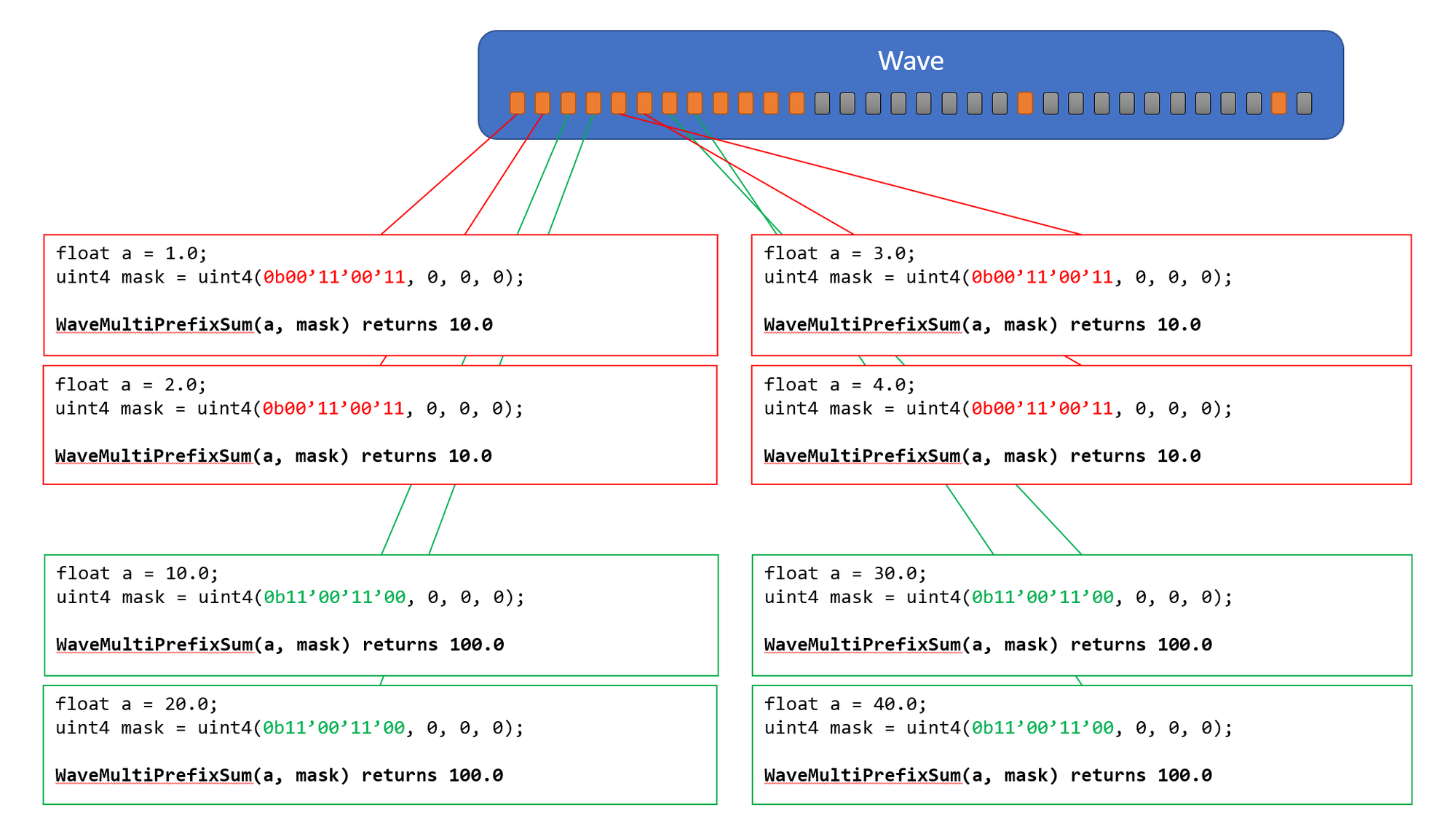
WaveMultiPrefixSum
引数に、読み取り対象となる変数を指定します。また、引数に128bit-wideのビットマスクとなる uint4 を指定します。
WaveActiveSumと動作は似ていますが、加算の対象となるLaneがビットマスクで指定されたLaneに限定される点が異なります。
ビットマスクは、Laneごとに設定を変更出来ますが、一つのLaneは1種類のビットマスクにしか所属する事ができません。
つまり、ビットマスクによって、Laneをパーティショニングしてサブセット化する事が出来ますが、各々のLaneが完全に自由にビットマスクを指定できるわけではありません。一つのLaneが複数の種類のビットマスクに所属した場合の動作は未定義です。
Waveのサイズを超えるBitやInactive Laneのビットは無視されます。(ビットがゼロとして扱います。)
このビットマスクの仕様は他のWaveMultiPrefix系と共通です。
WaveMultiPrefixProduct
引数に、読み取り対象となる変数を指定します。また、引数に128bit-wideのビットマスクとなるuint4を指定します。
WaveActiveProductと動作は似ていますが、乗算の対象となるLaneがビットマスクで指定されたLaneに限定される点が異なります。
WaveMultiPrefixCountBit
引数に、bool値を指定します。また、引数に128bit-wideのビットマスクとなるuint4を指定します。
WaveActiveCountBitと動作は似ていますが、乗算の対象となるLaneがビットマスクで指定されたLaneに限定される点が異なります。
WaveMultiPrefixBitAnd
引数に、読み取り対象となる整数型の変数を指定します。また、引数に128bit-wideのビットマスクとなるuint4を指定します。
WaveActiveBitAndと動作は似ていますが、乗算の対象となるLaneがビットマスクで指定されたLaneに限定される点が異なります。
WaveMultiPrefixBitOr
引数に、読み取り対象となる整数型の変数を指定します。また、引数に128bit-wideのビットマスクとなるuint4を指定します。
WaveActiveBitOrと動作は似ていますが、乗算の対象となるLaneがビットマスクで指定されたLaneに限定される点が異なります。
WaveMultiPrefixBitXor
引数に、読み取り対象となる整数型の変数を指定します。また、引数に128bit-wideのビットマスクとなるuint4を指定します。
WaveActiveBitXorと動作は似ていますが、乗算の対象となるLaneがビットマスクで指定されたLaneに限定される点が異なります。
終わりに
今回は、Wawve Intrinsicsの動作を理解するための基本的な内容となっているので、実際の使用ケースについては言及しませんでした。 次回は、もう少し実際の利用ケースについて触れたいと思います。
shikihuiku
リアルタイムレンダリングが好き