Importance Resampling 関連
参考資料
-
Importance Resampling for Global Illumination
https://scholarsarchive.byu.edu/cgi/viewcontent.cgi?article=1662&context=etd -
Rendering Millions of Dynamic Lights in Real-Time
https://news.developer.nvidia.com/rendering-millions-of-dynamics-lights-in-realtime/
Resampled Importance Sampling
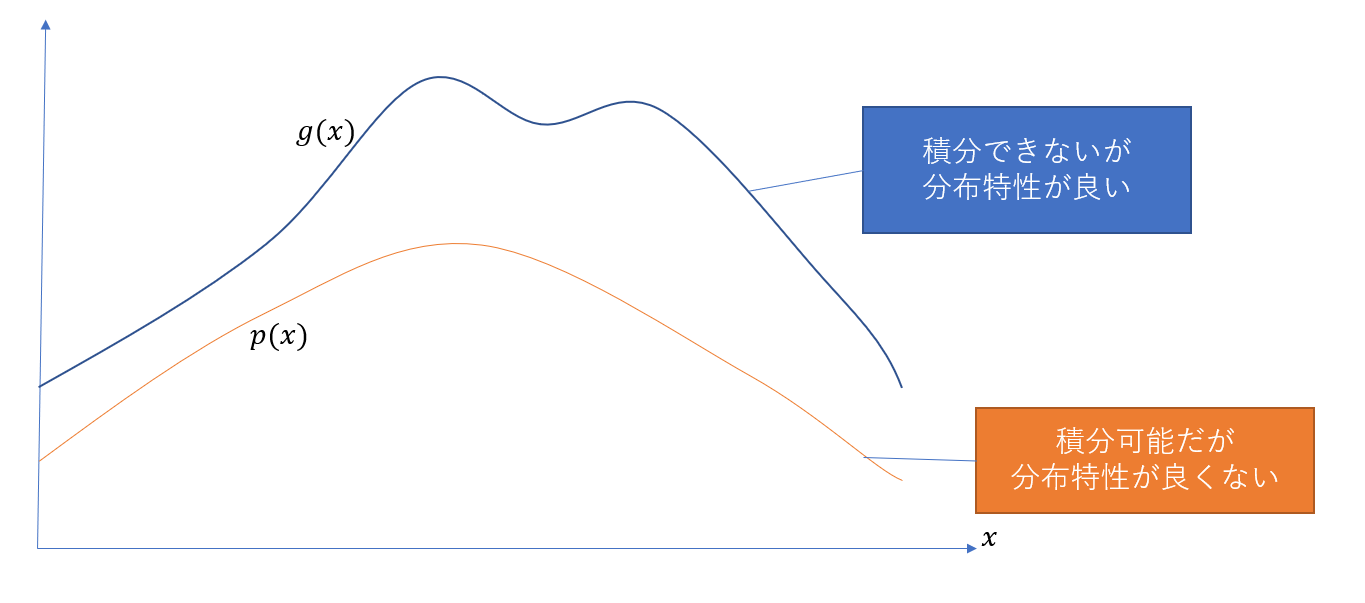
Importance Resamplingの概要
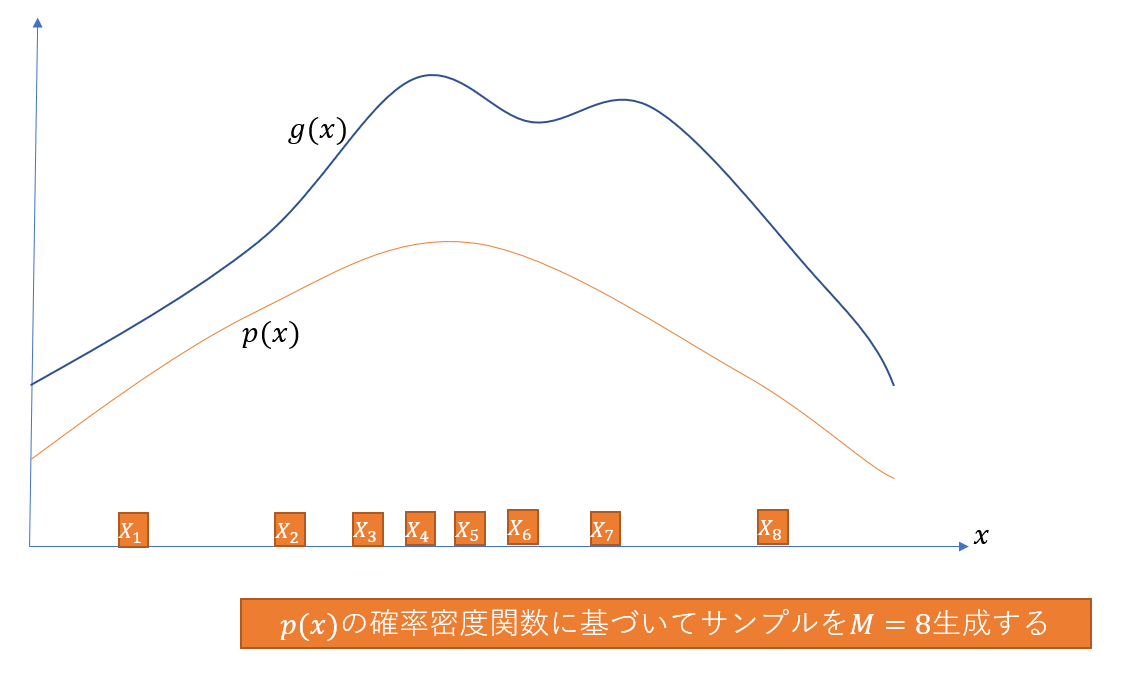
- 確率分布$p$に基づいたM個($(M \ge 1$)のサンプル、$(X = \langle X_1, X_2, … , X_M \rangle $を生成する
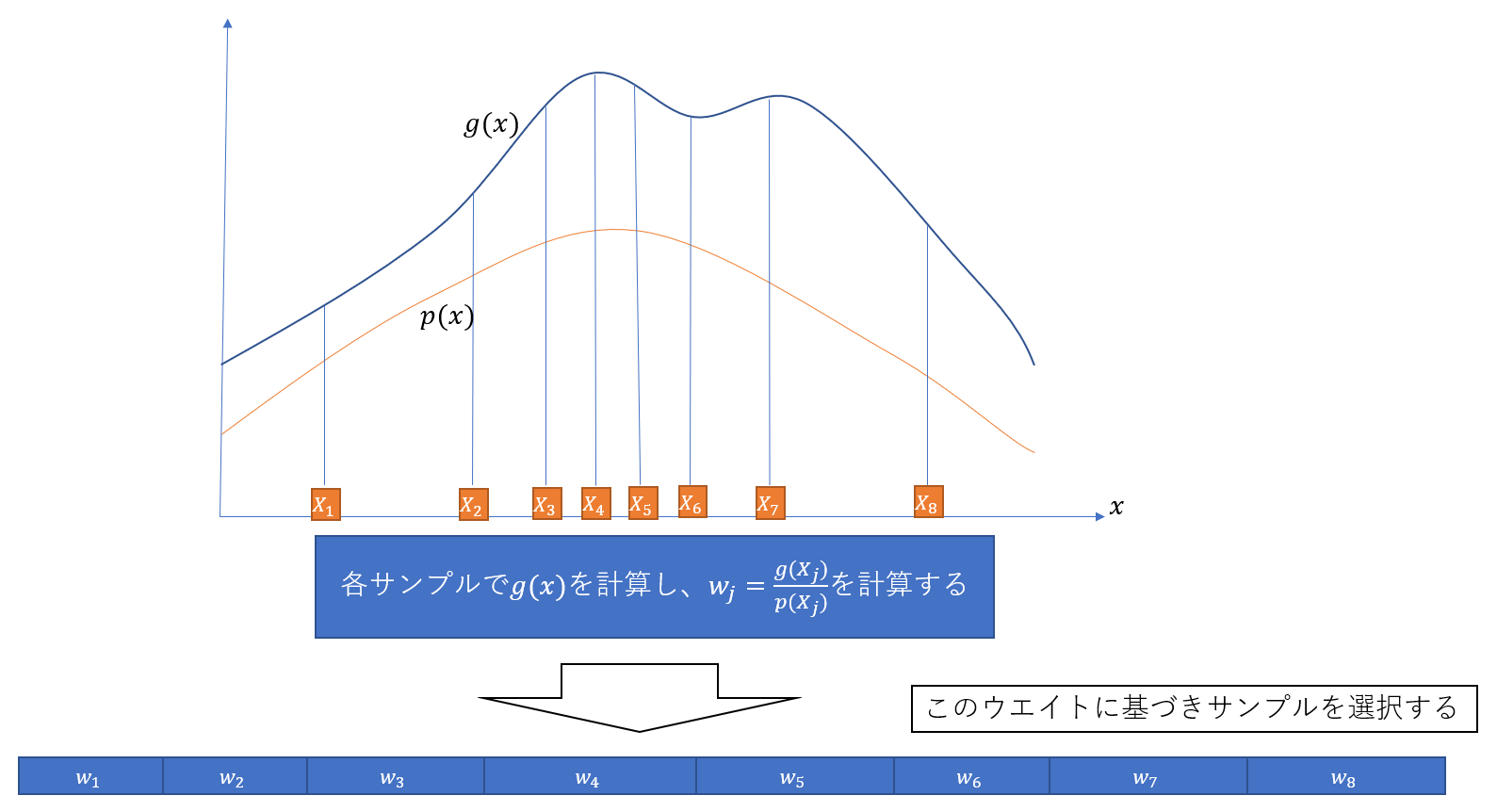
- 各サンプルのウエイト$w_j$を計算する
- $X$のなかから、一つのサンプル$Y$を、ウエイト$\langle w_1, w_2, … , w_M \rangle$に基づいて選ぶ
もし、$w_j = \frac{g(X_j)}{p(X_j)}$としたならば、サンプル$Y$は、おおよそ$g$に基づいて分布する。 上記のリサンプリングの効果とは、密度$p$のソースのから、サンプルを取り出し、“filter"することで、 結果として、サンプル$Y$がおおよそ$g$の分布になるようにすることである。
これを図解した下記の例は、8個のサンプルを生成して、それぞれのウエイトを計算した場合のイメージになる。
サンプル数である$M$を分布の補間変数としてとらえることができる。 $M=1$のとき、$Y$は$p$に従って分布する。$M\rightarrow\infty$とすると、$Y$の分布は$g$に近づく。 一般的には、$M$が有限個である事によって導入されるバイアスを無視できる程度に小さくするためには、$M$は非常に大きくなけれならない。
注釈:サンプル列$X$から、あるサンプル$Y$が選択される確率は $w_i / w_{sum}$で計算できるが、積分の範囲に対して、そのサンプルが選択される確率を考えると、 これに$M \cdot p(X_i)$を乗算する必要がある。したがって、そのサンプルが選択される確率は$M \cdot g(X_i) / w_{sum} $となる。これはそのまま次項でのImportance Samplingの確率となっている。また、$M / w_{sum} $は、サンプル列$X$において一定なので、$g(X_i)$に比例する関数で、選択が行われている事になる。
Resampled Importance Samplingの概要
Importance Resamplingの考え方をImporntace Samplingに導入したものをResampled Importance Sampling(RIS)と呼ぶ。
下記の積分を求めたいとする。
$$ I = \int_{\Omega} f(x) d\mu(x) $$
二つの確率密度関数$p$と、確率に即した値を返す関数$g$を導入する。 $p$は、比較的簡単に計算でき、正規化することができるが、上記積分をImportance Samplingするのにあまり良い分布となっていないとする。 $g$は、良い分布特性を持っているが、計算が複雑で正規化されていない、またはするのが困難だとする。 通常のImportance Samplingでは、$p$を使う事しかできないが、RISを使うことで、$g$の分布特性をunbiasedな条件下で使うことができる。 $X$(Resamplingによって生成されたサンプル列)および$Y$(Xからウエイトに基づいて乱択されたサンプル)がImporntace Resamplingを用いて導出された場合の、RISのEstimatorは以下の通りとなる。
$$ \hat I_{ris} = \frac{1}{N} \sum^{N}_{i=1} w(X_i, Y_i) \frac{f(Y_i)}{g(Y_i)} $$
ウエイト関数$w$は、$g$が正規化されていないことと、$Y$の分布が$g$を近似するようにする必要があることの二つを考慮して選択されなければならない。 そのための適切なウエイト関数$w$は実は非常に単純で、リサンプリングステップで計算された重みの平均である。
$$ w(X_i, Y_i) = \frac{1}{M} \sum^{M}_ {j=1} w_ {ij} = \frac{1}{M} \sum^{M}_ {j=1} \frac{g(X_{ij})}{p(X_{ij})}$$
注釈:$X_i$, $Y_i$はそれぞれが、Importance Samplingの$i$番目の試行の時に作られた、M個のサンプル列$X_i$と、そこから選択された一つのサンプル$Y_i$を指す。 $w_{ij}$は、Importance Samplingの$i$番目の試行の時に作られた、M個のサンプル集合の、$j$番目のサンプルのウエイトを指す。
注釈2:ウエイトは、結局のところ、二つの関数$p(x)$と$g(x)$のプロファイル(関数の形状および大きさ)の比になる。(例えば、$g(x)$が$p(x)$に対して、平均で2倍の値を持つ場合は、 $g(Y_i)$で除算すると、推定値が期待値の$1/2$に収束してしまう。$w$はその補正として2倍の補正を掛ける役割を担う。)
上記の2式を合わせると下記の通りになる。 $$ \hat I_{ris} = \frac{1}{N} \sum^{N}_ {i=1} \left( \frac{f(Y_i)}{g(Y_i)} \cdot \frac{1}{M} \sum^{M}_ {j=1} \frac{g(X_{ij})}{p(X_{ij})} \right) $$
$M=1$のときは、RISは$p$によるImportance Samplingになる。RISがunbiasedである条件は、$f$が非ゼロの領域では、$p, q$共に非ゼロである必要があるのと、$M,N$共にゼロより大きい必要がある。 RISがunbiasとすると、誤差は分散に起因するもののみとなる。ターゲット分布関数$g$と共に、パラメーター$M,N$を適切に選ぶことが分散の低減につながる。
レンダリングにおいて、ライティングの関数を$f=F_s GVL_e$とするとき、ターゲット分布関数$g$を、$g=F_s GL_e$とすることができる。レイのトラバースが必要な$V$項を取り除いたものである。正規化されている必要がないのでそのまま使用できる。
次は、適切な$M,N$の設定である。
Robust Approximations of M and N
詳細は割愛するが、最適なM,Nを選ぶための計算には、実際のモンテカルロ法の試行が必要になる。しかし実際にはモンテカルロ法の試行の前に知りたい。 ここではサンプルの生成や実際の推定値の計算にかかる時間を基にして、$M,N$の導出を行う。 $T_x$を$p$に基づいてサンプルを生成してウエイトを計算するのにかかる時間とし、$T_y$をIRS Estimatorで推定値を計算する時間とすると、全体の計算時間は以下の様になる。 $$ T=MNT_x + N(r(M) + T_y) $$ $r$はリサンプリングにかかる時間で、離散的な分布からサンプルを選ぶ作業は高度に最適化されており、時間は無視できるとすると以下の様になる。 $$ T=MNT_x + NT_y $$
ここで、リサンプリングの各ステップに同じ計算時間を割り当てるとすると、以下の様になる。 $$MNT_x = NT_y $$
この条件下では$M$は以下の様に求まる。 $$M=\frac{T_y}{T_x} $$
注釈:$N$は上式から求まらないが、総計算時間の関数として計算することができる。$M$は、$T_y$($V$項を含んだシェーディングの評価)が、他の項の計算に比べてどのくらい時間がかかるかによって 決定されるといえると思う。時間がかかればかかるほど$M$を大きくした方が良いという事になる。
レンダリングするシーンの複雑度が均一であれば、この値は事前計算することができる。$T_x, T_y$を得るために数千のPrimaryRayをキャストして計算する。
参照論文 のレンダリングの例では、二つのポリゴンライトと環境マップを用いてライティングしている。この場合RISは同じ計算量で分散を70%低減できた。しかし、ライティングから環境マップを取り除くと、分散を10%しか低減出来なかった。 これは、$L_e$の成分にあった環境マップが分散を導入していたからで、これはターゲット分布関数$g$のウエイトとして計算されていた。(つまり$L_e$が導入した分散に効果的に作用した。) しかし、これが取り除かれると、$V$項による分散が支配的となり、通常のImportance Samplingとの差が得られなくなった。
Weighted Reservoir Sampling
上記Resampled Importance Samplingは、計算時に$M$個のサンプルストリームを用意する必要があった。これを、実際にストレージを確保して保存することなく実現するための手法がWeighted Reservoir Samplingになる。 WRSではサンプルストリームに値を追加するたびにDraw(分布に基づく乱択)を行う代わりに、ストリームに何個要素を追加しても、ウエイトの合計値である$w_ {sum}$と現在の出力である$y$のみ記録することでRISと同等の機能を実現する。
Weighted Reservoir Samplingの手法
以下はWRSのpuseudo codeである。サンプルストリームの要素の追加(update)のたびに、$w_ {sum}$を更新しつつ乱択を行う。Reservoirは常に選択候補となる一つのサンプルを保持する形となる。同じストリームから複数のサンプルを乱択することは出来ないが、必要なストレージが非常に少ないのが特徴。
class Reservoir
y ← 0 // The output sample
w ← 0 // The weight for the output stream
wsum ← 0 // The sum of weights
M ← 0 // The number of samples seen so far
function p(x)
return probability of x
function g(x)
return target distribution of x
function update(xi, wi, cnt)
wsum ← wsum + wi
M ← M + cnt
if rand() < (wi /wsum) then
y ← xi
function reservoirSampling()
Reservoir r
for i ← 1 to StreamLen do
generate xi
r.update(xi, g(xi)/p(xi), 1)
w ← (1 / g(y))(wsum / M)
return y, w
Combine Multiple Reservoirs
WRSの特長として、個々のストリームにアクセスすることなく、生成された複数のストリームを結合することができることが挙げられる。結合の方法は以下の通りで新しいReservoirに、結合するReservoirを入力することで行う。 s.update()の第二引数のウエイトは、結合する際のReservoirのターゲット分布関数$g$が同じ場合は、r.wsumと等価である。しかし、結合する際のReservoirのターゲット分布関数が異なる場合、 $g(y)/g’(y)$をr.wsumに乗算する必要がある。 これはそのための計算である。
function combineReservoirs(g, r1, r2, . . . , rk)
Reservoir s // a new reservor
foreach r ∈ {r1, . . . , rk } do
s.update(r.y, g(r.y) · r.w · r.M, r.M)
w ← (1 / g(s.y))(s.wsum / s.M)
return s.y, w
注釈1:ウエイトのスケーリング(g(r.y) · r.w · r.M)について。
結合元の$w$は、
$$\frac{1}{g’(y’)} \frac{1}{M’} \sum^{M’}_ {i=1} \frac{g’(X_i)}{p’(X_i)} $$
なのだが、これは通常のImportance Samplingにおける確率密度関数の逆数に相当するものでなくてはならない。(通常1/p(x)で表すが本式のpとは意味が異なる。)
したがって、これに$g(y’)$ を乗算すると、以下の様になり、これは、通常のRISの一つのウエイトである、$g / p$と同義になる。(ただし、この場合のベースの確率密度関数(先ほどpと呼んでいたものに相当するもの)が実際にどんなプロファイルかは知らない)
$$\frac{g(y’)}{g’(y’)} \frac{1}{M’} \sum^{M’}{i=1} \frac{g’(X_i)}{p’(X_i)} $$
そして、この$y’$は、$M’$個のサンプルの中から選択されたサンプルなので、加重平均で確率計算するために、その分のウエイトに相当する$M’$を乗算する。
$$\frac{g(y’)}{g’(y’)} \sum^{1}{M’} \frac{g’(X_i)}{p’(X_i)} $$
このように、ウエイトのスケーリングを解釈する事ができる。
また、結合後のウエイトの計算部分((1 / g(s.y))(s.wsum / s.M))は、まず、(s.wsum / s.M)の部分は、全てのサンプルのg/pの平均値になり、関数pとgのプロファイルの比と考える事ができる。
また、この値は、全てのサンプルのg/pの平均値なので、候補となった全サンプルにおいて一定の値と解釈でき、最終的な確率密度の逆数は、1/gに比例していると考える事ができる。
注釈2:Biasについて。
実際には、結合先と結合元で、確率密度関数や、ターゲット分布関数が異なれば、もとから一つのサンプル集合だった場合とは異なる演算になる。ただ、これによってBiasが導入されるかは別である。
実際は、結合結果として選択されたサンプルが、結合元の確率密度関数でゼロになる場合にBiasが導入されることになる。この場合は、無効なウエイト値が計算に入るので、実際の値より小さくなる方向にBiasがかかるはずである。
それ以外では、結果的に分散を大きくするかもしれないが、Biasが導入されることはない。
Naive Unbiased combine
UnbiasedなWRSの結合をするためには、結合前のターゲット分布関数もしくは、確率密度関数が必要になる。(正確にはその両方。p(), g()の両方が非ゼロである事が確認できる必要がある) Reservoirを結合してサンプルの選択をするところまでは同じだが、最後に、選択されたサンプルが、結合前のターゲット分布関数で有効であるかどうかを確認して、無効であればウエイトから除外するようにしている。
function combineReservoirsUnbiased(g, r1, r2, . . . , rk, g1, g2, . . . , gk)
Reservoir s // a new reservor
s.combineReservoirs(g, r1, r2, . . . , rk)
Z ← 0
foreach gi ∈ {g1, . . . , gk } do
if gi(s.y) > 0 then
Z ← Z + ri.M
w ← (1 / g(s.y))(s.wsum / Z)
return s.y, w
なぜこれでUnbiasedになるか
一見すると、$\frac{w_{sum}}{M}$を乗算する代わりに、$\frac{w_{sum}}{Z}$を乗算するが、一方で$w_{sum}$の計算時には、結合前のターゲット分布関数の値に関わらず加算をしているので 矛盾しているように見える。ここで簡単な例を使って考えてみる。
ReSTIR のFig7で使われている$p(), g()$を例として、$p_1()$で作られた一つの$M_1$個のサンプルのReservoirと、$p_2()$で作られた$M_2$個のReservoir を結合する場合を考える。$g(), p1(), p2()$はそれぞれ以下の通りで、$p_2()$は0.5を超えるとゼロになる。
- $ g(x) = 2 -2x$, $ p_1(x) = 1$
- $ g(x) = 2 -2x$, $ p_2(x) = 2H(1/2 -x) $(p2(x)=0 if x > 0.5 otherwise =2)
ここで、p1側のReservoirが、0.6のサンプルを選択していて、p2側のReservoirが0.3のサンプルを選択している状態だとする。この二つを結合した結果、0.6のサンプルが選択された場合のBiased 結合によるウエイトは以下の様に計算される。 $$\frac{1}{g(0.6)} \frac{g(0.6) · w_1 · M_1 + g(0.3) · w_2 · M_2}{M_1 + M_2} $$ ここで、さらに簡単にするため、$M_1=M_2=1$とすると、上記の式は以下の様になる。 $$\frac{1}{g(0.6)} \frac{g(0.6)/p_1(0.6) + g(0.3)/p_2(0.3)}{2} $$ 一方で、最初の定義より、$p_2(0.6)$がゼロである事が分かっているので、p2側のReservoirから0.6のサンプルが生成されることは無い。ここで改めて、0.6のサンプル発生からの結合の過程を通じて、最終的に0.6のサンプルが選択される確率考えると、p1側のReservoirに0.6というサンプルが発生する確率と、結合したときにp1側が選択される同時確率で表す事ができる。 $$ p1(0.6) \frac{g(0.6)/p_1(0.6)}{g(0.6)/p_1(0.6) + g(0.3)/p_2(0.3)} $$ この式より分かることは、$M_1+M_2=2$で除算しているBiased 結合は実際の発生確率の逆数よりも小さい値になることが分かる。そしてそれをUnbiased にするには、2では無く1、すなわち$M$ではなく$Z$で除算するのが正しい事が分かる。 念のため、$M_1$と$M_2$に対する条件を自由した場合に、$p_1$側が選択される確率は以下の様に表す事ができる。 $$ \frac{1}{w_1} \frac{g(0.6) · w_1 · M_1}{g(0.6) · w_1 · M1 + g(0.3) · w_2 · M_2} $$
ここからも、$M$ではなく$Z$で除算することでBiasが排除できる事が分かる。
結合時の安定性について
ReSTIR のFig7では、結合時の数値安定性についても言及している。
先の$p_2$を以下の様に変更し、全域で発生確率が非ゼロになるが、0.5を超えると非常に小さい確率となるように変更している。
$ p_2(x) = max(1.9…H(1/2 -x), 10^{-4}) $(p2(x)=10^{-4} if x > 0.5 otherwise =1.9…)
このようにした場合に、先の単純な例を用いて、$p_1$側から0.3、$p_2$側から0.6、そして結合による選択で0.6が選択された場合のウエイトは以下の様に算出される。 $$\frac{1}{g(0.6)} \frac{g(0.3)/p_1(0.3) + g(0.6)/p_2(0.6)}{2} $$ 一方で、p1側から0.6、p2側から0.3、そして結合による選択で0.6が選択された場合のウエイトは以下の様に算出される。 $$\frac{1}{g(0.6)} \frac{g(0.6)/p_1(0.6) + g(0.3)/p_2(0.3)}{2} $$ 先の通り、$p_2(0.6)$は極小なので、$g(0.6)/p_2(0.6)$は極大化する。両者はどちらも0.6を出力するが、サンプルが発生した経緯でウエイトが大きく異なるうえに、$p_2$側は極稀にしか発生しない。 安定した値に収束させるには非常に数多くの、結合後のサンプルが必要となる。
MIS Combineについて
ReSTIR の4.3項では、MISを使った結合に言及している。 これも、先ほどUnbiasedの説明をした例を使って考える。以下の式は、$p_1$側から0.6が生成されて結合した際に0.6が選択される確率と、$p_2$側から0.6が生成されて0.6選択される場合の確率である。 選択されない側のサンプルは単にxとしているがこれにあまり深い意味はない。 $$ \frac{1}{w_1} \frac{g(0.6) · w_1 · M_1}{g(0.6) · w_1 · M1 + g(x) · w_2 · M_2} $$ $$ \frac{1}{w_2} \frac{g(0.6) · w_2 · M_2}{g(x) · w_1 · M1 + g(0.6) · w_2 · M_2} $$ 端的に言えば、$p_1, p_2$を結合した後に0.6が出力されるのは上記2つのうちのいずれかである。また、結合した結果$p_1$側を選択した場合に算出されるウエイトは以下の通りだが、 $$\frac{1}{g(0.6)} \frac{g(0.6) · w_1 · M_1 + g(x) · w_2 · M_2}{M_1 + M_2} $$ これを少し変形すると以下の様に書ける。 $$\frac{M_1}{M_1 + M_2} \frac{1}{g(0.6) · M_1} \{g(0.6) · w_1 · M_1 + g(x) · w_2 · M_2\} $$ このとき、先頭の項にある$\frac{M_1}{M_1 + M_2}$を$p_1$側のサンプリング戦略のMISウエイトと見做すことができる。そして$p_2$側も同様に考える事ができ、MISウエイトの合計値が1なので、Biasが発生することもない。 つまり、結合時のMISウエイトは、各サンプリング戦略のサンプル数の加重平均であると言える。また、MISウエイトは、その値のサンプルを出力する可能性のあるサンプル戦略のウエイトの合計値が1になるのであれば、どのようなウエイトでもBiasを導入することは無いことが知られている。これを利用して、先の項で説明した結合時の安定性を改善する事ができる。例えば論文にある通り、各戦略での初期サンプルの発生確率の加重平均にする事もできる。 ここで、$x_s$は最終的に選択されたサンプルの値で、$S$はサンプリング戦略数。$p_s()$は各サンプリング戦略の初期サンプル発生確率である。 $$ \frac{p_s(x_s)}{\sum^{S}_{i=1}p_i(x_s)} $$ このようにすれば、先の$p_2(0.6)$のような極小の確率で発生するサンプルがあった場合に、最終的なImportanceWeightの極大化を防ぐ事ができる。
閑話休題 ReSTIR のFig7について
まずは、グラフ(a)(b)について。
被積分関数については言及がないが$ f(x) = 2-2x$と仮定する。
- $ g(x) = 2 -2x$, $ p_1(x) = 1$
- $ g(x) = 2 -2x$, $ p_2(x) = 2H(1/2 -x) $(p2(x)=0 if x > 0.5 otherwise =2)
としている。
$1/p(y)$をVisualizeしているといってるが、この$1/p(y)$はRISのEffectivePDFの逆数、つまり、$\frac{1}{g(y)} \frac{1}{M} \sum^{M}_ {i=1} \frac{g(X_i)}{p(X_i)} $を指していると思われる。
-
一つは、サンプルのヒストグラムの逆数をプロットしたもの
Importance Samplingを、$f(x)$に沿って行えたとするならば、生成されたサンプルのヒストグラムは、$f(x)$に比例しなくてはならない。 したがって、サンプルのヒストグラムを正規化して逆数をとれば、$1/f(x)$に沿うと考えられる。このグラフは、サンプル数に基づいて、ヒストグラムを正規化して逆数にしたグラフと思われる。 $p_2$が0.5以上のサンプルを生成しないので、そこに大きな境界が出来ている。(実際の運用なら単純によろしくない。) 0.5以上は、$p_1$の方で生成されるが、こちらのサンプル確率は単純に$g(x)$(つまりf(x))に比例しているため、 1に近づくにつれてサンプルの生成される確率が低下している。それに伴ってヒストグラムの乱れが顕著に見られる様になっていると思われる。また、0.5以下ではサンプル数が多い傾向があり、0.5以上ではサンプル数が少ない傾向があるが、これは$p_2$が偏った範囲でサンプルを生成することによる影響と思われる。 -
もう一つは、RISのウエイトの平均値
こちらは単純に先のRISのウエイト(実質的なサンプルの確率としてのウエイト。Effective PDF)の逆数の平均だから解釈は簡単。サンプルの出現確率と、RISのウエイト値は、統計的に一致していない場合は、真値からのBiasが生じる事になる。 グラフ(a)は、0.5以上で、明らかな乖離が見られる。サンプルを発生させない$p_2$のウエイトを算入しているためBiasが発生しているのが分かる。
次に、グラフ(c)(d)について。
$ p_2(x) = max(1.9…H(1/2 -x), 10^{-4}) $ (p2(x)=10^{-4} if x > 0.5 otherwise =1.9…)
に変更し、$p_2$で非常に低確率で0.5以上のサンプルが生成されるように変更したもの。
-
0.5以上のサンプルが生成されるとき、$p_2=10^{-4}$なので、$\frac{g(X_i)}{p(X_i)} $の部分は値が非常に大きくなると思われる。すると、$p_2$内でのResamplingで選択される可能性が高く、 また、$p_2$の$w_{sum}$も大きくなることから、$p_1,p_2$を結合する時に選択される可能性が高くなる。 また結合後の$w_{sum}$への影響も大きいので、選択の可否に関わらず、$p_2$側で、0.5以上のサンプルが生成されることにより、最終的なウエイト値に大きな乱れを導入する原因になっている。(c)
-
MIS(おそらく初期サンプルの発生確率の加重平均)で結合する場合、各サンプリング戦略(この場合は、結合対象の各RISのこと。いわゆる$p_1,p_2$)における初期サンプルの確率が計算出来なくてはならない。しかし、RISでは、自身のサンプル戦略の結果として出たサンプルのウエイト値(サンプルの確率)は計算されるるが、任意のサンプルの確率を計算する術がない。しかしここでは何らかのサンプルの確率に相当するものが計算できるものとして話を進める。
$p_2$で非常に低確率な0.5以上のサンプルが出た場合は、RISのウエイトは極大化するはずである。しかしMISウエイトを初期サンプルの発生確率の加重平均にすれば、極小化した出現確率による除算は高確率で相殺することができる。(d)
ReSTIRのSupplementary Filesの方に記載があるMISに関する議論
こちら のSupplementary Documentでは、RISを結合する際のMISのウエイトの計算方法について
言及している。この手法にとってとても重要な部分なのだが、とにかくこちらに記載がある。
二つの手法が紹介され、一つはTalbot et alの手法と、本論文の提案手法である、Bitterli et alの手法を比較している。質の良いMISウエイトを計算するには、任意のサンプルの、個々のサンプル戦略に於けるPDFが計算できる必要があるが、RISは、自身が選出したサンプルのウエイト値(PDFの逆数に相当する値)を計算することしかできない。そこで、PDFの代替となる値を計算する必要がある。重要なのは、この値はMISのウエイトを計算するためのもので、各サンプリング戦略(各RIS)におけるPDFと必ずしも一致する必要がない。
ただ、unbiasedなウエイトを算出するだけなら、
- あるサンプルに於ける各サンプリング戦略のウエイトの合計値が1
- ある戦略で、あるサンプルのPDFがゼロならば、そのウエイトはゼロ の二つを守れば良い。
Talbot et alの方法は、各RISを結合の際に、結合対象サンプルを、全てのRISのターゲット分布関数:$g$で評価してウエイト$g_i / g_{sum}$を計算し、正規化($m$の平均が1.0になるように)して、これをサンプルのウエイト値に乗算して結合している。直感的で分かりやすい。上記の項で説明したMIS Combineというよりは、結合時の各戦略の選択確率のモジュレーションと解釈した方が適切だと思われる。 ターゲット分布関数:$g$の評価回数が2次的に増大するのがこの方法の大きな欠点である。
function combineReservoirsTalbotMIS(g, r1, r2, . . . , rk, g1, g2, . . . , gk)
Reservoir s // a new reservor
foreach r_i ∈ {r1, . . . , rk } do
// calculate normalized MIS weight using g()
g_sum ← 0
foreach g_j ∈ {g1, . . . , gk } do
g_sum ← g_sum + g_j(r.y)
m ← g_i(r.y) / (g_sum / k)
s.update(r.y, g(r.y) · r.w · r.M · m, r.M)
w ← (1 / g(s.y))(s.wsum / s.M)
return s.y, w
本論文の提案手法であるBitterli et alの手法では、結合して、最終的に選択されたサンプルを使って、各戦略のターゲット分布関数の加重平均でMISウエイトを計算している。 最終的に$1/M$の代わりにこれを乗算している。この手法では、ターゲット分布関数の評価回数はサンプリング戦略数(結合するRISの数)なので、 Talbot et alの方法に比べたら、明らかに計算量が少ない。
注釈:この式はまだ理解できてない。例えば一つの戦略で、Mに非常に大きな数を使った場合、s.wsumはそれに準じて大きな数になる。
一方でmは、ターゲット分布関数に変化が無い場合、サンプリング戦略数が増えればそれに準じて小さな値になっていくはずである。
これら両者は直交したパラメーターで、直接の関係がない。しかし、s.wsum · mは、1/gを正規化するために作用する必要があるが、これでは正規化できないはずだ。
もし、全てのサンプリング戦略でMが1であると仮定すると、g(r.y) · r.wの部分はg/pに相当して、s.wsumは、サンプリング戦略数分の$\sum{g/p}$で、サンプリング戦略数で割ればg/pの平均値として解釈できる。
一方でmは、各サンプリング戦略のターゲット分布関数が同じものだった場合は、サンプリング戦略数の逆数となる。選択されたサンプルのターゲット分布関数が、
他の戦略に対して相対的に大きければ、ウエイトが大きくなり、逆ならば小さくなるようなMISウエイトとして解釈できる。
function combineReservoirsMIS(g, r1, r2, . . . , rk, g1, g2, . . . , gk)
Reservoir s // a new reservor
foreach r ∈ {r1, . . . , rk } do
s.update(r.y, g(r.y) · r.w · r.M, r.M)
// calculate normalized MIS weight using g()
g_sum ← 0
foreach g_j ∈ {g1, . . . , gk } do
g_sum ← g_sum + g_j(r.y)
m ← g_*(r.y) / g_sum // g_* : target distribution that contributed s.y
w ← (1 / g(s.y))(s.wsum · m)
return s.y, w
私の考えでは、上記の記載は、すべてのRISのMが1である場合は正しく動作するが、それ以外では誤りで、選択されたRISのMの値$M_s$で除算しなくてはならないはずである。
w ← (1 / (g(s.y) * Ms)) (s.wsum · m)
shikihuiku
リアルタイムレンダリングが好き